我将使用中文进行翻译,如下:
我想要读取一个包含逗号分隔数字的 *.csv 文件。
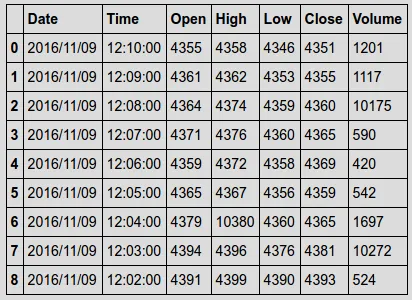
例如:
File.csv
Date, Time, Open, High, Low, Close, Volume
2016/11/09,12:10:00,'4355,'4358,'4346,'4351,1,201 # The last value is 1201, not 201
2016/11/09,12:09:00,'4361,'4362,'4353,'4355,1,117 # The last value is 1117, not 117
2016/11/09,12:08:00,'4364,'4374,'4359,'4360,10,175 # The last value is 10175, not 175
2016/11/09,12:07:00,'4371,'4376,'4360,'4365,590
2016/11/09,12:06:00,'4359,'4372,'4358,'4369,420
2016/11/09,12:05:00,'4365,'4367,'4356,'4359,542
2016/11/09,12:04:00,'4379,'1380,'4360,'4365,1,697 # The last value is 1697, not 697
2016/11/09,12:03:00,'4394,'4396,'4376,'4381,1,272 # The last value is 1272, not 272
2016/11/09,12:02:00,'4391,'4399,'4390,'4393,524
...
2014/07/10,12:05:00,'10195,'10300,'10155,'10290,219,271 # The last value is 219271, not 271
2014/07/09,12:04:00,'10345,'10360,'10185,'10194,235,711 # The last value is 235711, not 711
2014/07/08,12:03:00,'10339,'10420,'10301,'10348,232,050 # The last value is 242050, not 050
实际上,它有7列,但最后一列的某些值有逗号,而pandas会将它们视为额外的列。
我的问题是,如果有任何方法可以让pandas只读取前6个逗号并忽略其余的逗号,或者是否有任何方法可以删除第6个逗号之后的逗号(我很抱歉,我想不到任何可以做到这一点的功能)。
感谢您阅读这个 :)