我正在尝试在两个Spark RDD之间进行连接。我有一个与类别相关联的交易日志。我已经格式化了我的交易RDD,将类别ID作为键。
transactions_cat.take(3)
[(u'707', [u'86246', u'205', u'7', u'707', u'1078778070', u'12564', u'2012-03-02 00:00:00', u'12', u'OZ', u'1', u'7.59']),
(u'6319', [u'86246', u'205', u'63', u'6319', u'107654575', u'17876', u'2012-03-02 00:00:00', u'64', u'OZ', u'1', u'1.59']),
(u'9753', [u'86246', u'205', u'97', u'9753', u'1022027929', u'0', u'2012-03-02 00:00:00', u'1', u'CT', u'1', u'5.99'])]
categories.take(3)
[(u'2202', 0), (u'3203', 0), (u'1726', 0)]
事务日志的大小约为20GB(3.5亿行)。 类别列表小于1KB。
当我运行
transactions_cat.join(categories).count()
Spark开始变得非常缓慢。我有一个包含643个任务的阶段。前10个任务需要大约1分钟。然后每个任务都变得越来越慢(大约在第60个任务时需要15分钟左右)。我不确定出了什么问题。
请查看这些截图以获得更好的理解。
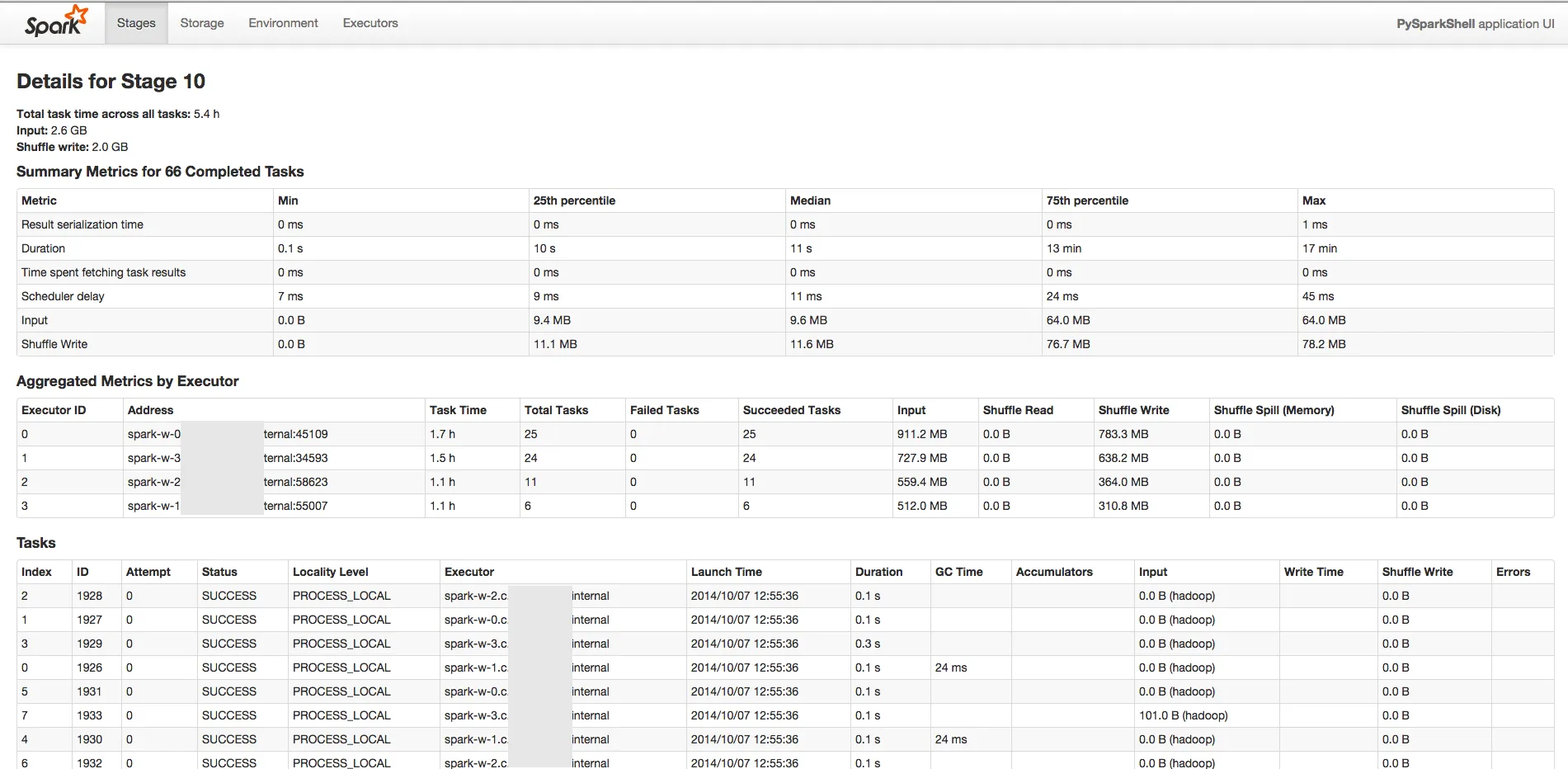
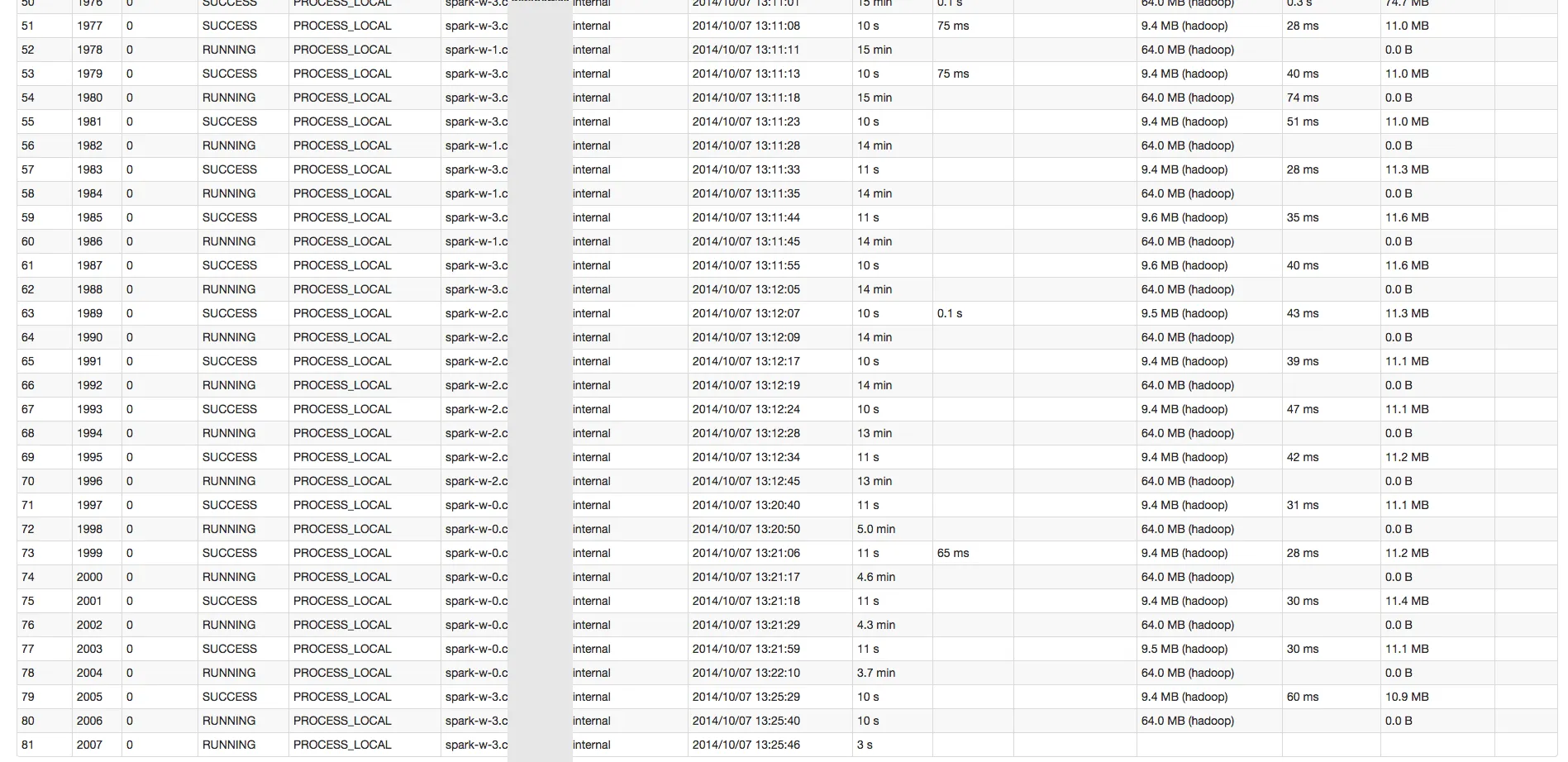

我正在使用Python shell运行Spark 1.1.0,使用4个工作节点,总内存为50 GB。 仅计算交易RDD非常快(30分钟)。