我正在尝试理解RIDL漏洞类别。
这是一种漏洞类型,能够从各种微架构缓冲区中读取陈旧数据。
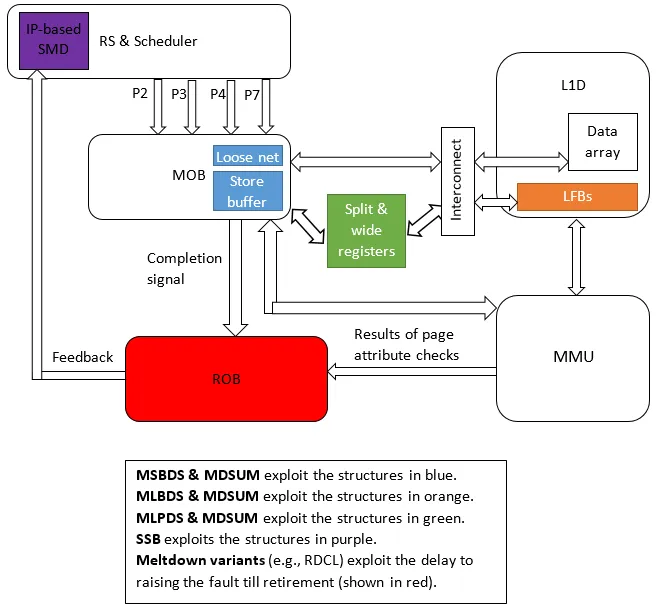
今天已知的漏洞利用:LFB、加载端口、eMC和存储缓冲区。
所链接的论文主要关注于LFB。
我不明白为什么CPU会使用LFB中的陈旧数据来满足负载。
我可以想象,如果负载命中L1d,则会在内部“重播”,直到L1d将数据带入LFB并向OoO核心发出停止“重播”的信号(因为现在读取的数据是有效的)。
然而我不确定"replay"具体指什么。我认为负载被分配到一个负载可用的端口,然后记录在负载缓冲区(在MOB中),并最终保持需要直到它们的数据可用(由L1信号)。所以我不确定"replaying"是如何发挥作用的,此外对于RIDL工作,每次尝试"play"负载也应该解除阻塞的依赖指令。这对我来说很奇怪,因为CPU需要跟踪哪些指令在负载正确完成后重新播放。
关于RIDL的论文使用以下代码作为示例(不幸的是我不得不将其粘贴为图像,因为PDF布局不允许我复制它):
这在几行以下似乎得到了证实:
具体而言,我们可能期望两个访问都很快,不仅仅是对应于泄漏信息的一个。毕竟,当处理器发现自己的错误并在第6行重新启动时,程序也将使用此索引访问缓冲区。
但我希望CPU在转发LFB(或任何其他内部缓冲区)中的数据之前检查负载的地址。
除非CPU实际上重复执行负载,直到它检测到已加载的数据现在有效(即重放)。
但是,为什么每次尝试都会解除依赖指令的阻塞?
如果存在重放机制,则它的工作方式是什么,以及它如何与RIDL漏洞交互?
然而我不确定"replay"具体指什么。我认为负载被分配到一个负载可用的端口,然后记录在负载缓冲区(在MOB中),并最终保持需要直到它们的数据可用(由L1信号)。所以我不确定"replaying"是如何发挥作用的,此外对于RIDL工作,每次尝试"play"负载也应该解除阻塞的依赖指令。这对我来说很奇怪,因为CPU需要跟踪哪些指令在负载正确完成后重新播放。
关于RIDL的论文使用以下代码作为示例(不幸的是我不得不将其粘贴为图像,因为PDF布局不允许我复制它):

这在几行以下似乎得到了证实:
具体而言,我们可能期望两个访问都很快,不仅仅是对应于泄漏信息的一个。毕竟,当处理器发现自己的错误并在第6行重新启动时,程序也将使用此索引访问缓冲区。
但我希望CPU在转发LFB(或任何其他内部缓冲区)中的数据之前检查负载的地址。
除非CPU实际上重复执行负载,直到它检测到已加载的数据现在有效(即重放)。
但是,为什么每次尝试都会解除依赖指令的阻塞?
如果存在重放机制,则它的工作方式是什么,以及它如何与RIDL漏洞交互?