我认为@BeeOnRope的答案完全回答了我的问题。基于@BeeOnRope的答案和评论,我想在这里添加一些额外的细节。特别是,我将展示如何确定性能事件是否在所有负载步幅中每次迭代发生固定次数。
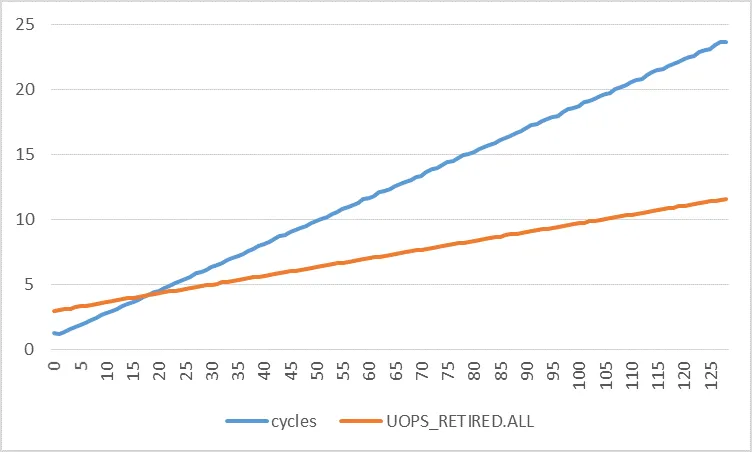
通过查看代码,很容易看出执行单个迭代需要3个微操作。前几次加载可能会错过L1缓存,但之后的所有加载都会命中缓存,因为所有虚拟页面都映射到同一个物理页面,而Intel处理器中的L1是物理标记和索引。所以是3个微操作。现在考虑UOPS_RETIRED.ALL性能事件,当微操作退役时会发生此事件。我们预计会看到大约3 * 迭代次数的这种事件。执行期间发生的硬件中断和页面故障需要微码辅助来处理,这可能会扰动性能事件。因此,对于性能事件X的特定测量,每个计数事件的来源可能是:
- 被分析代码的指令。让我们称其为X1。
- 用于引发由被分析代码尝试的内存访问引起的页面故障的微操作。让我们称其为X2。
- 用于调用中断处理程序的微操作,由于异步硬件中断或引发软件异常。让我们称其为X3。
因此,X = X1 +X2 + X3。
由于代码很简单,我们能够通过静态分析确定X1 = 3。但是我们对X2和X3一无所知,它们可能不是每次迭代都恒定不变的。但是我们可以使用UOPS_RETIRED.ALL来测量X。幸运的是,对于我们的代码,页面故障的数量遵循正常模式:每个访问的页面恰好一个(可以使用perf进行验证)。合理地假设引发每个页面故障所需的工作量相同,因此每次都会对X产生相同的影响。请注意,这与每个迭代的页面故障数不同,对于不同的负载步幅也不同。每个访问的页面上直接由于执行循环而退役的微操作数量是恒定的。我们的代码不会引发任何软件异常,因此我们不必担心它们。那硬件中断呢?嗯,在Linux上,只要我们在未分配给处理鼠标/键盘中断的核心上运行代码,那么真正重要的中断就是本地APIC计时器。幸运的是,这个中断也会定期发生。只要每个页面花费的时间相同,计时器中断对X的影响将在每个页面上恒定。
我们可以简化前面的等式:
X = X1 + X4.
因此,对于所有的负载步长,
(每页X) - (每页X1) = (每页X4) = 常数。
现在我将讨论为什么这很有用,并提供使用不同性能事件的示例。我们需要以下符号:
ec = total number of performance events (measured)
np = total number of virtual memory mappings used = minor page faults + major page faults (measured)
exp = expected number of performance events per iteration *on average* (unknown)
iter = total number of iterations. (statically known)
请注意,通常情况下,我们不知道或不确定我们感兴趣的性能事件,这就是为什么我们需要进行测量的原因。退休的uops的情况很容易解决。但总的来说,这就是我们需要实验性地找出或验证的内容。本质上,
exp是性能事件
ec的计数,但不包括那些由于页面故障和中断而引起的事件。
基于上述论点和假设,我们可以得出以下方程式:
C = (ec/np) - (exp*iter/np) = (ec - exp*iter)/np
这里有两个未知数:常数
C和我们感兴趣的值
exp。因此,我们需要两个方程才能计算出这些未知量。由于该方程对所有步幅都成立,我们可以使用两个不同步幅的测量值:
C = (ec
1 - exp*iter)/np
1
C = (ec
2 - exp*iter)/np
2
我们可以找到
exp:
(ec
1 - exp*iter)/np
1 = (ec
2 - exp*iter)/np
2
ec
1*np
2 - exp*iter*np
2 = ec
2*np
1 - exp*iter*np
1
ec
1*np
2 - ec
2*np
1 = exp*iter*np
2 - exp*iter*np
1
ec
1*np
2 - ec
2*np
1 = exp*iter*(np
2 - np
1)
因此,
exp = (ec
1*np
2 - ec
2*np
1)/(iter*(np
2 - np
1))
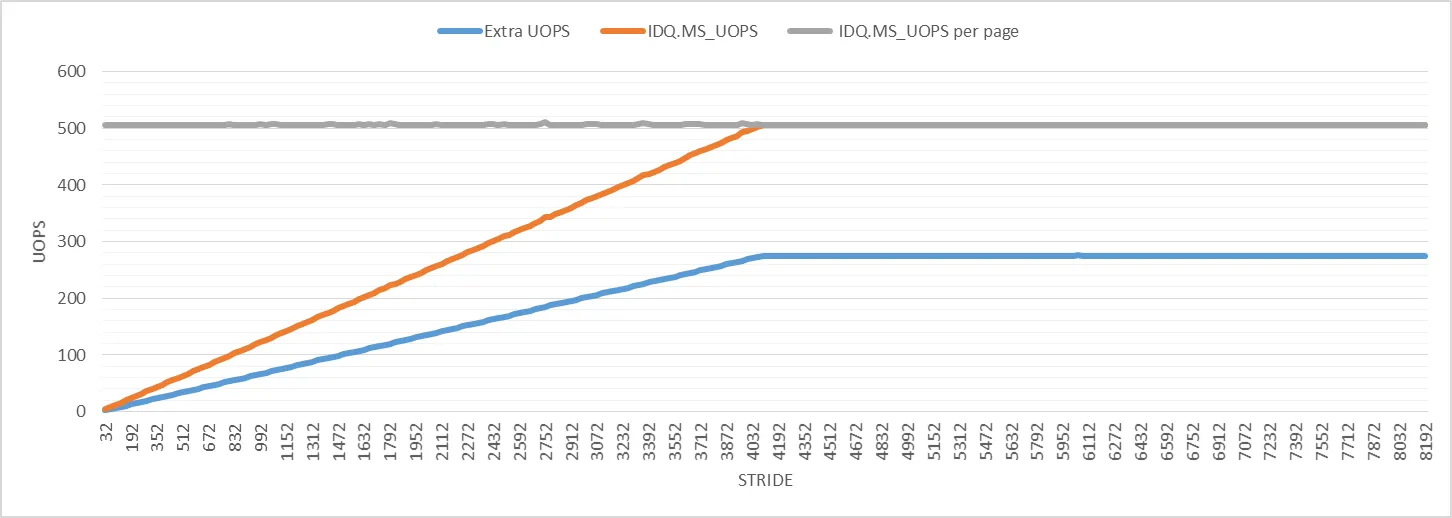
让我们将此方程应用于
UOPS_RETIRED.ALL。
stride
1 = 32
iter = 1000万
np
1 = 1000万 * 32 / 4096 = 78125
ec
1 = 51410801
stride
2 = 64
iter = 1000万
np
2 = 1000万 * 64 / 4096 = 156250
ec
2 = 72883662
exp = (51410801*156250 - 72883662*78125)/(10m*(156250 - 78125))
= 2.99
很好!非常接近预期的每次迭代3个已退役uops。
C = (51410801 - 2.99*10m)/78125 = 275.3
我已经计算出所有步幅的
C。它不是一个完全的常数,但对于所有步幅来说,它都是275+-1。
exp可以类似地推导其他性能事件:
MEM_LOAD_UOPS_RETIRED.L1_MISS: exp = 0
MEM_LOAD_UOPS_RETIRED.L1_HIT: exp = 1
MEM_UOPS_RETIRED.ALL_LOADS: exp = 1
UOPS_RETIRED.RETIRE_SLOTS: exp = 3
那么这对所有性能事件都适用吗?嗯,让我们尝试一些不太明显的东西。例如考虑 RESOURCE_STALLS.ANY,它测量了任何原因造成的分配器停顿周期。仅仅通过查看代码很难确定应该有多少 exp。注意到对于我们的代码,RESOURCE_STALLS.ROB和RESOURCE_STALLS.RS为零。只有RESOURCE_STALLS.ANY在这里是显著的。利用exp的方程和不同步长的实验结果,我们可以计算exp。
步长1 = 32
迭代次数 = 1000万
np1 = 1000万 * 32 / 4096 = 78125
ec1 = 9207261
步长2 = 64
迭代次数 = 1000万
np2 = 1000万 * 64 / 4096 = 156250
ec2 = 16111308
exp = (9207261*156250 - 16111308*78125)/(10m*(156250 - 78125))
= 0.23
C = (9207261 - 0.23*10m)/78125 = 88.4
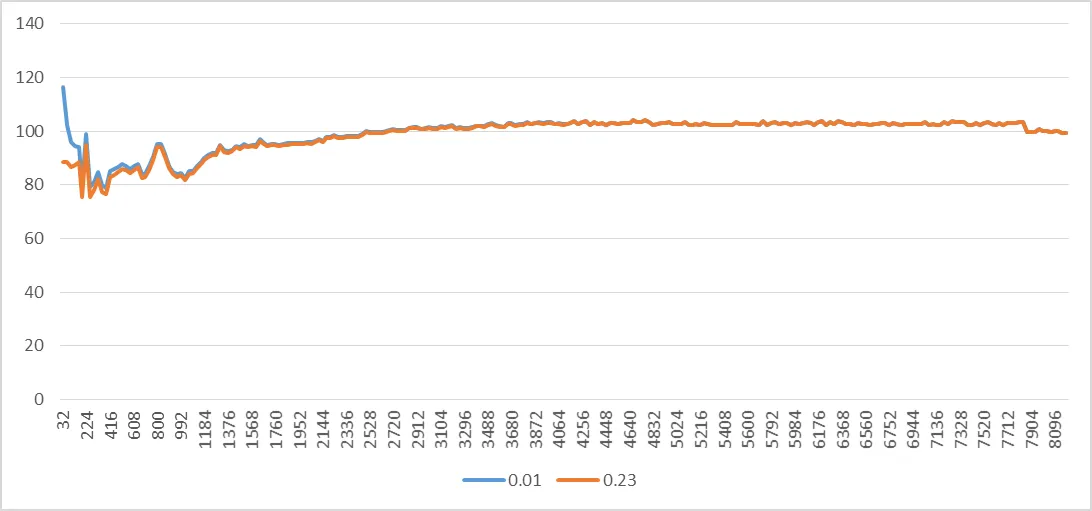
我已经为所有步长计算了C。看起来它并不是常数。也许我们应该使用不同的步长?试试也无妨。
步长1 = 32
迭代次数1 = 1000万
np1 = 1000万 * 32 / 4096 = 78125
ec1 = 9207261
步长2 = 4096
迭代次数2 = 100万
np2 = 100万 * 4096 / 4096 = 100万
ec2 = 102563371
exp = (9207261*1m - 102563371*78125)/(1m*1m - 10m*78125))
= 0.01
C = (9207261 - 0.23*10m)/78125 = 88.4
(请注意,这次我使用了不同数量的迭代,只是为了展示您可以这样做。)
我们得到了一个不同的值exp。我已经为所有步幅计算了C,它仍然看起来不是常数,如下图所示。对于较小的步幅,它变化明显,2048之后略微变化。这意味着有一个或多个假设,即每页固定数量的分配器停顿周期无效。换句话说,不同步幅的分配器停顿周期的标准差是显著的。
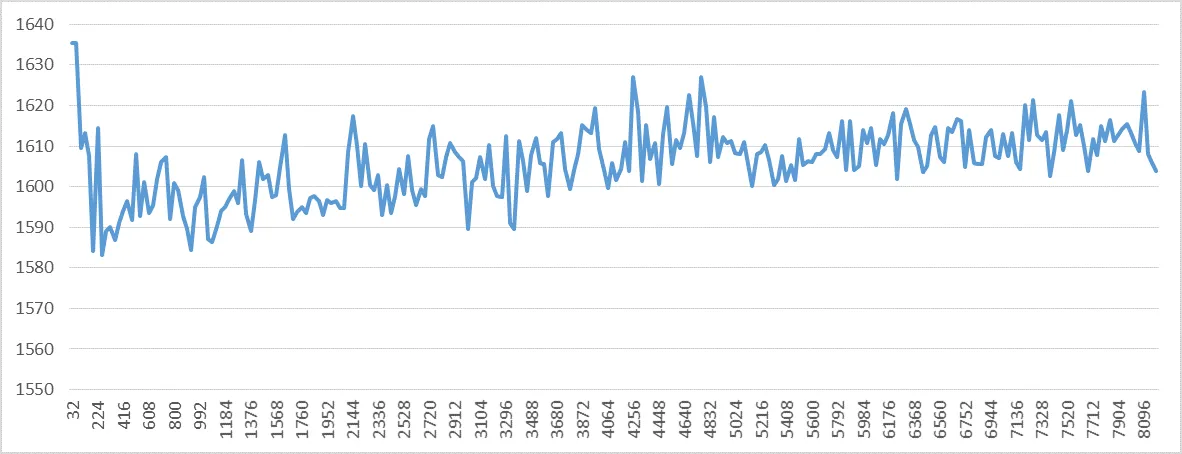
对于UOPS_RETIRED.STALL_CYCLES性能事件,exp = -0.32,标准差也很显著。这意味着有一个或多个假设,即每页固定数量的退役停顿周期无效。
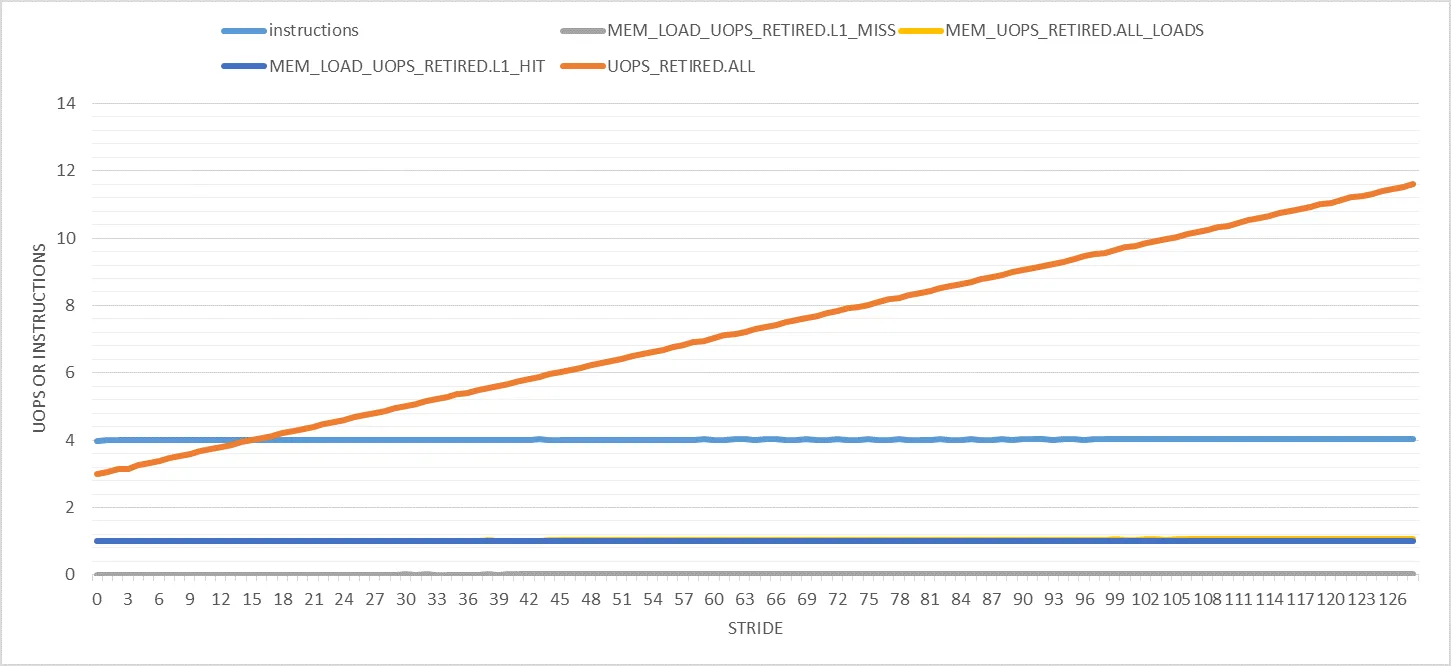
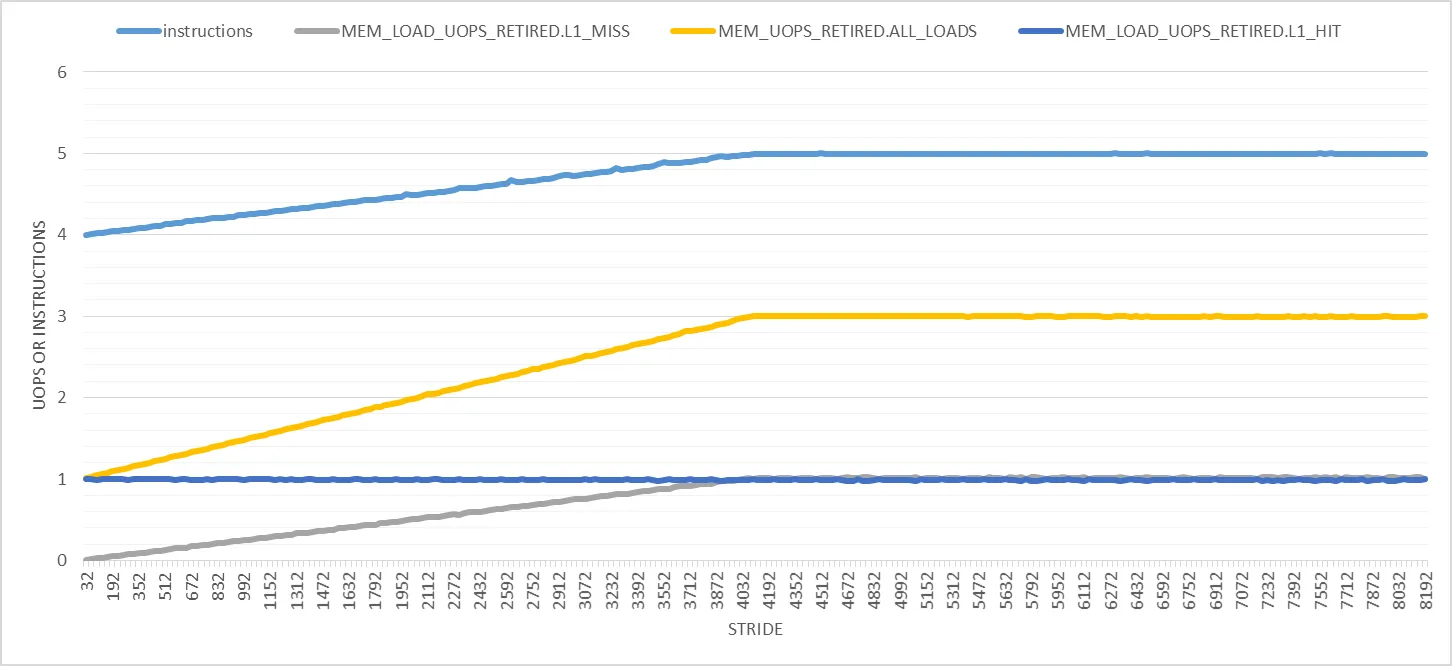
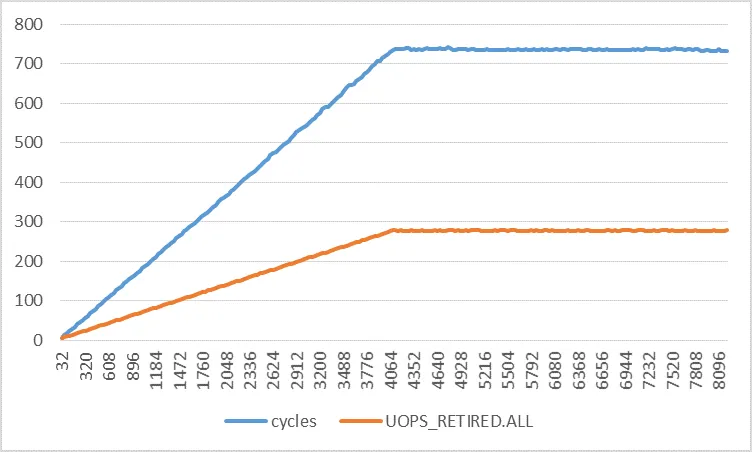
我开发了一种简单的方法来纠正测量到的退役指令数。 每个触发的页面错误将向已退休指令计数器添加一个额外的事件。例如,假设页面错误在固定的迭代次数后定期发生,比如2次。也就是说,每两次迭代触发一次故障。当步幅为2048时,这在问题代码中发生。由于我们希望每次迭代有4条指令退役,因此直到发生页面错误的预期退役指令总数为4*2 = 8。由于页面错误会向已退役指令计数器添加一个额外的事件,因此它将被测量为9而不是8。也就是说,每次迭代4.5。当我实际测量2048步幅案例的退役指令计数时,它非常接近4.5。在所有情况下,当我应用此方法静态预测每次迭代测量到的已退役指令的值时,误差始终小于1%。尽管存在硬件中断,但这非常精确。我认为只要总执行时间少于50亿个核心周期,硬件中断就不会对已退役指令计数器产生任何重大影响。(我的每个实验都不超过50亿个周期,这就是为什么。)但是,如上所述,必须始终注意故障发生的次数。
如上所述,有许多性能计数器可以通过计算每页值来进行校正。另一方面,退役指令计数器可以通过考虑获取页面错误的迭代次数来进行校正。RESOURCE_STALLS.ANY和UOPS_RETIRED.STALL_CYCLES也可能类似于退役指令计数器进行校正,但我还没有调查过这两个计数器。
p0156uops)。所以基本上当一个load输入到另一个load时,只会重新执行load,因为它是唯一的依赖操作。如果之后有ALU操作,则将重新执行ALU操作。有时候会重播超过一个uop,包括非直接依赖的操作,看起来会重放在load执行的一个周期内的uops。 - BeeOnRope