我的第一步是通过RCurl :: getURL()和rjson :: fromJSON()加载数据,与您第二个代码示例相同:
library(rjson);
library(RCurl);
URL <- 'https://fm.formularynavigator.com/jsonFiles/publish/11/47/providers.json';
jsonRList <- fromJSON(getURL(URL));
接下来,为了深入了解数据的结构和清洁度,我编写了一组辅助函数:
levelApply <- function(
nodes,
keyList,
func=identity,
...,
joinFunc=NULL
) {
if (length(keyList) == 0L) {
ret <- if (is.null(nodes)) NULL else func(nodes,...)
} else if (is.null(keyList[[1L]]) || length(keyList[[1L]]) != 1L) {
ret <- lapply(if (is.null(keyList[[1L]])) nodes else nodes[keyList[[1L]]],levelApply,keyList[-1L],func,...,joinFunc=joinFunc);
if (!is.null(joinFunc))
ret <- do.call(joinFunc,ret);
} else {
ret <- levelApply(nodes[[keyList[[1L]]]],keyList[-1L],func,...,joinFunc=joinFunc);
};
ret;
};
levelApplyToVec <- function(...) levelApply(...,joinFunc=c);
levelApplyToFrame <- function(...) levelApply(...,joinFunc=rbind);
理解上述内容的关键在于
keyList参数。假设你有如下列表:
list(NULL,'addresses',2:3,'city')
那将选择所有主列表下地址列表下第二个和第三个地址元素下的城市字符串。在R中没有内置的应用函数可以操作这样的“并行”节点选择(rapply()接近,但不完全相同),这就是为什么我编写了自己的函数。levelApply()查找每个匹配的节点并在其上运行给定的func()(默认为identity(),因此返回节点本身),将结果作为joinFunc()连接或以与输入列表中存在的那些节点相同的递归列表结构返回给调用者。快速演示:
unname(levelApplyToVec(jsonRList,list(4L,'addresses',1:2,c('address','city'))));
## [1] "1001 Noble St" "Fairbanks" "1650 Cowles St" "Fairbanks"
以下是我在解决这个问题的过程中编写的其他辅助函数:
keyCombos <- function(node,keyList,allKeys) `rownames<-`(setNames(unique(as.data.frame(levelApplyToFrame(node,keyList,function(h) allKeys%in%names(h)))),allKeys),NULL);
keyCombosWithCount <- function(node,keyList,allKeys) { ks <- keyCombos(node,keyList,allKeys); ks$.count <- unname(apply(ks,1,function(combo) sum(levelApplyToVec(node,keyList,function(h) identical(sort(names(ks)[combo]),sort(names(h))))))); ks; };
tl <- function(e) { if (is.null(e)) return(NULL); ret <- typeof(e); if (ret == 'list' && !is.null(names(e))) ret <- list(type='namedlist') else ret <- list(type=ret,len=length(e)); ret; };
tlStr <- function(e) { if (is.null(e)) return(NA); ret <- tl(e); if (is.null(ret$len)) ret <- ret$type else ret <- paste0(ret$type,'[',ret$len,']'); ret; };
mkcsv <- function(v) paste0(collapse=',',v);
keyListToStr <- function(keyList) paste0(collapse='','/',sapply(keyList,function(key) if (is.null(key)) '*' else paste0(collapse=',',key)));
keyTypes <- function(node,keyList,allKeys) data.frame(key=allKeys,tl=sapply(allKeys,function(key) mkcsv(unique(na.omit(levelApplyToVec(node,c(keyList,key),tlStr))))),row.names=NULL);
rowToFrame <- function(dfrow) data.frame(column=names(dfrow),value=c(as.matrix(dfrow)));
getNPIRow <- function(df,npi) which(df$npi == npi);
npiToFrame <- function(df,npi) rowToFrame(df[getNPIRow(df,npi),]);
我试图记录下我最初检查该数据时运行的命令序列。以下是结果,显示了我运行的命令、命令输出以及前导注释,描述了我的意图,以及我从输出中得出的结论:
levelApplyToVec(jsonRList,list(),tlStr);
unique(levelApplyToVec(jsonRList,list(NULL),tlStr));
allKeys <- unique(levelApplyToVec(jsonRList,list(NULL),names)); allKeys;
keyCombosWithCount(jsonRList,list(NULL),allKeys);
keyTypes(jsonRList,list(NULL),allKeys);
unique(levelApplyToVec(jsonRList,list(NULL,'addresses',NULL),tlStr));
allAddressKeys <- unique(levelApplyToVec(jsonRList,list(NULL,'addresses',NULL),names)); allAddressKeys;
keyCombosWithCount(jsonRList,list(NULL,'addresses',NULL),allAddressKeys);
keyTypes(jsonRList,list(NULL,'addresses',NULL),allAddressKeys);
unique(levelApplyToVec(jsonRList,list(NULL,'plans',NULL),tlStr));
allPlanKeys <- unique(levelApplyToVec(jsonRList,list(NULL,'plans',NULL),names)); allPlanKeys;
keyCombosWithCount(jsonRList,list(NULL,'plans',NULL),allPlanKeys);
keyTypes(jsonRList,list(NULL,'plans',NULL),allPlanKeys);
allNameKeys <- unique(levelApplyToVec(jsonRList,list(NULL,'name'),names)); allNameKeys;
keyCombosWithCount(jsonRList,list(NULL,'name'),allNameKeys);
keyTypes(jsonRList,list(NULL,'name'),allNameKeys);
这里是数据的摘要:
- 一个顶级主列表,长度为3256。
- 每个元素都是一个哈希表,键集不一致。在所有主哈希表中总共有12个键,有3种不同的键集模式。
- 其中6个哈希值是标量字符串,3个是可变长度的字符串向量,`addresses`是可变长度的列表,`plans`是长度始终为9的列表,而`name`是一个哈希表。
- 每个`addresses`列表元素都是一个哈希表,具有5或6个键到标量字符串,其中`address_2`是不一致的。
- 每个`plans`列表元素都是一个哈希表,具有3个键到标量字符串,没有不一致之处。
- 每个`name`哈希表都有`first`和`last`,但不一定有`middle`标量字符串。
最重要的观察结果是,在并行节点之间没有类型不一致(除了省略和长度差异)的情况。这意味着我们可以将所有并行节点组合成向量,而无需考虑类型强制转换。只要将所有列与足够深的节点相关联,使得所有列对应于输入列表中的单个标量字符串节点,就可以将所有数据展平为二维结构。
下面是我的解决方案。请注意,它依赖于我之前定义的辅助函数`tl()`、`keyListToStr()`和`mkcsv()`。
extractLevelColumns <- function(
nodes,
...,
keyList=list(),
sep=NULL,
mkname=function(keyList,maxLen) paste0(collapse='.',if (is.null(sep) && maxLen == 1L) keyList[-length(keyList)] else keyList)
) {
cat(sprintf('extractLevelColumns(): %s\n',keyListToStr(keyList)));
if (length(nodes) == 0L) return(list());
tlList <- lapply(nodes,tl);
typeList <- do.call(c,lapply(tlList,`[[`,'type'));
if (length(unique(typeList)) != 1L) stop(sprintf('error: inconsistent types (%s) at %s.',mkcsv(typeList),keyListToStr(keyList)));
type <- typeList[1L];
if (type == 'namedlist') {
allKeys <- unique(do.call(c,lapply(nodes,names)));
ret <- do.call(c,lapply(allKeys,function(key) extractLevelColumns(lapply(nodes,`[[`,key),...,keyList=c(keyList,key),sep=sep,mkname=mkname)));
} else if (type == 'list') {
lenList <- do.call(c,lapply(tlList,`[[`,'len'));
maxLen <- max(lenList,na.rm=T);
allIndexes <- seq_len(maxLen);
ret <- do.call(c,lapply(allIndexes,function(index) extractLevelColumns(lapply(nodes,function(node) if (length(node) < index) NULL else node[[index]]),...,keyList=c(keyList,index),sep=sep,mkname=mkname)));
} else if (type%in%c('raw','logical','integer','double','complex','character')) {
lenList <- do.call(c,lapply(tlList,`[[`,'len'));
maxLen <- max(lenList,na.rm=T);
if (is.null(sep)) {
ret <- lapply(seq_len(maxLen),function(i) setNames(data.frame(sapply(nodes,function(node) if (length(node) < i) NA else node[[i]]),...),mkname(c(keyList,i),maxLen)));
} else {
ret <- list(setNames(data.frame(sapply(nodes,function(node) if (length(node) == 0L) NA else if (maxLen == 1L) node else paste(collapse=sep,node)),...),mkname(keyList,maxLen)));
};
} else stop(sprintf('error: unsupported type %s at %s.',type,keyListToStr(keyList)));
if (is.null(ret)) ret <- list();
ret;
};
flattenList <- function(mainList,...) do.call(cbind,extractLevelColumns(mainList,...));
extractLevelColumns()函数遍历输入列表,提取每个叶节点位置的所有节点值,将它们合并为一个向量,并在缺失值处使用NA,然后转换为一个列数据框。该函数立即设置列名,利用参数化的
mkname()函数将
keyList的字符串化定义为字符串列名。多列作为数据框的列表从每个递归调用以及顶级调用中返回。
它还验证了并行节点之间没有类型不一致。虽然我之前手动验证了数据的一致性,但我尝试编写尽可能通用和可重用的解决方案,因为这样做总是一个好主意,所以这个验证步骤是适当的。
flattenList()是主要的接口函数;它只是调用
extractLevelColumns(),然后调用
do.call(cbind,...)将列组合成单个数据框。
此解决方案的优点是完全通用的;由于是完全递归的,因此可以处理无限数量的深度级别。此外,它没有包依赖项,参数化列名称构建逻辑,并将可变参数转发到
data.frame(),因此例如您可以传递
stringsAsFactors=F来抑制
data.frame()通常对字符列进行的自动因子化,和/或
row.names={namevector}来设置结果数据框的行名,或者
row.names=NULL以防止使用输入列表中存在的顶级列表组件名称作为行名。
我还添加了一个默认为
NULL的
sep参数。如果为
NULL,则将多元素叶节点分隔成多个列,每个元素一个列,并在列名上添加索引后缀以区分。否则,它被视为字符串分隔符,用于将所有元素连接到单个字符串中,并仅为该节点生成一个列。
在性能方面,它非常快速。下面是一个演示:
system.time({ df <- flattenList(jsonRList); });
结果:
class(df); dim(df); names(df);
生成的data.frame非常宽,但我们可以使用rowToFrame()和npiToFrame(),以每次一行的方式来获得良好的垂直布局。例如,这是第一行:
rowToFrame(df[1L,])
我已经进行了许多对单个记录的点检测,对结果进行了相当彻底的测试,一切看起来都是正确的。如果您有任何问题,请告诉我。
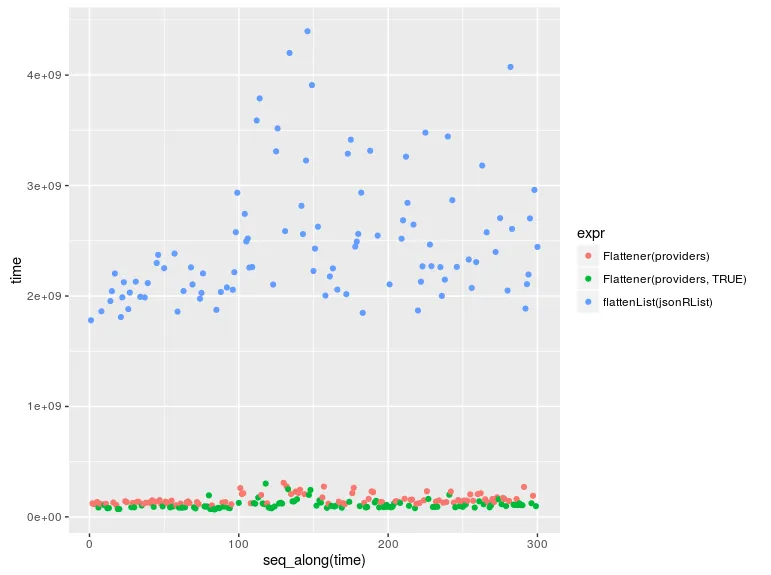
jsonRList,也找不到它的在线文档。 - Gabriel Fair