这里有第三种方法可以不需要编写任何Python代码来完成。它只使用终端中的
ImageMagick,它已经安装在大多数Linux发行版上,并且也可用于macOS和Windows。
基本上,它使用了与我的其他答案相同的技术-阈值、中值滤波器和
"Connected Components Analysis",也就是
"labelling"。
magick article.jpg -colorspace gray -threshold 95% -median 19x19 \
-define connected-components:verbose=true \
-define connected-components:area-threshold=100 \
-connected-components 4 -auto-level output.png
样例输出
Objects (id: bounding-box centroid area mean-color):
4: 963x241+38+333 519.0,453.0 231939 srgb(0,0,0)
0: 1045x590+0+0 528.0,204.0 155279 srgb(255,255,255)
2: 393x246+292+73 488.0,195.5 96534 srgb(0,0,0)
3: 303x246+698+73 849.0,195.5 74394 srgb(0,0,0)
1: 238x246+39+73 157.5,195.5 58404 srgb(0,0,0)
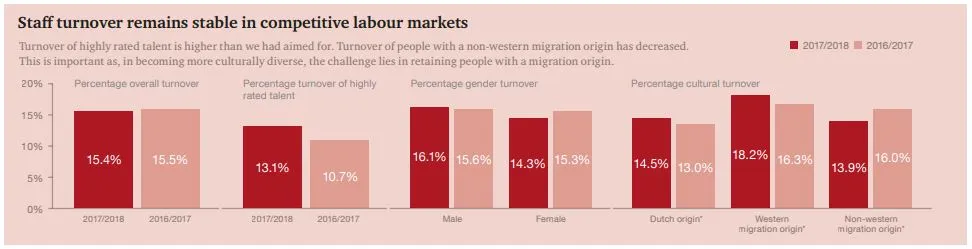
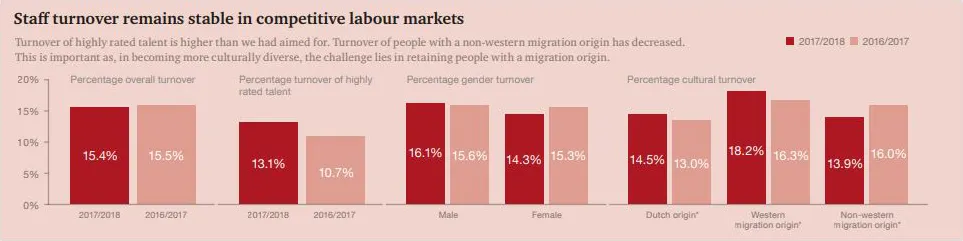
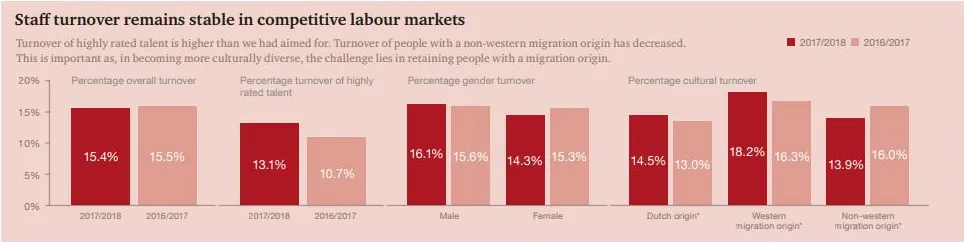
输出结果的开头会告诉你每个字段是什么,然后每行代表一张图片中找到的一个 blob。让我们看看这一行:
2: 393x246+292+73 488.0,195.5 96534 srgb(0,0,0)
这意味着有一个宽393像素,高246像素的图块,在左上角偏移292,73处,我们可以使用以下半透明蓝色绘制:
magick article.jpg -fill "rgba(0,0,255,0.5)" -draw "rectangle 292,73 685,319" result.png
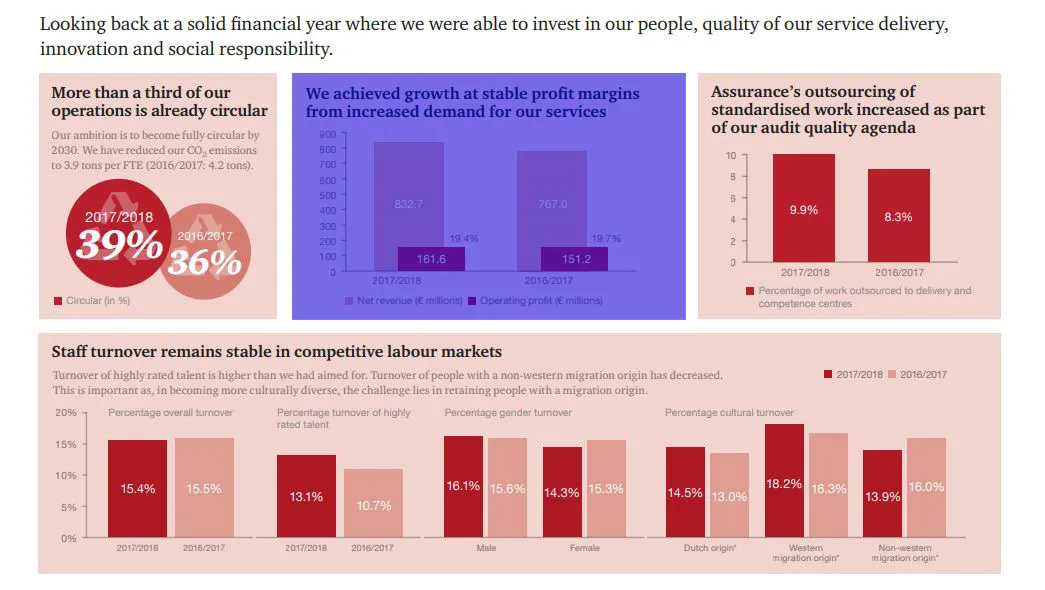
我们可以使用以下方法进行裁剪:
magick article.jpg -crop 393x246+292+73 result.png
下面是翻译的结果:
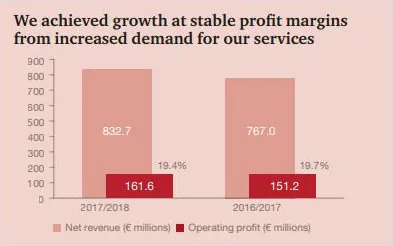
从第一个命令产生的标记图像(output.png)如下所示-您会发现每个blob都以不同的颜色(灰度值)进行标记:
请注意,如果您的ImageMagick版本为v6或更早版本,则需要在所有上述命令中使用convert而不是magick。




img变量中拥有整个图像,你可以裁剪另一部分并将其保存在一个新变量中。 - Gábor Fekete