背景
下面这段用 C++ 写的数值软件的关键循环,基本上是通过比较两个对象的一个成员来进行的:
for(int j=n;--j>0;)
asd[j%16]=a.e<b.e;
a和b属于ASD类:
struct ASD {
float e;
...
};
我正在研究将此比较放入轻量级成员函数中的影响:
bool test(const ASD& y)const {
return e<y.e;
}
并像这样使用它:
for(int j=n;--j>0;)
asd[j%16]=a.test(b);
编译器正在内联该函数,但问题是汇编代码将不同,导致运行时间开销超过10%。我必须质疑:
问题
1.为什么编译器生成不同的汇编代码?
2.为什么生成的汇编速度较慢?
编辑:通过实现@KamyarSouri的建议(j%16),第二个问题已得到回答。汇编代码现在看起来几乎相同(请参见http://pastebin.com/diff.php?i=yqXedtPm)。唯一的区别是第18、33、48行。
000646F9 movzx edx,dl
材料
- 测试代码:http://pastebin.com/03s3Kvry
- 使用 /Ox /Ob2 /Ot /arch:SSE2 在 MSVC10 上的汇编输出:
此图表显示我的代码进行了50次测试后的 FLOP/s(经过缩放因子)。
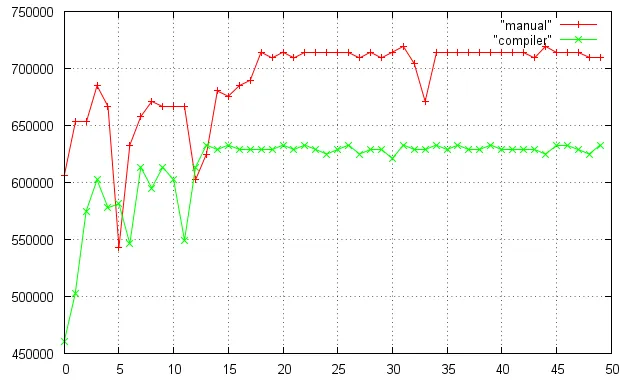
生成图表的gnuplot脚本: http://pastebin.com/8amNqya7
编译器选项:
/Zi /W3 /WX- /MP /Ox /Ob2 /Oi /Ot /Oy /GL /D "WIN32" /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /Gm- /EHsc /MT /GS- /Gy /arch:SSE2 /fp:precise /Zc:wchar_t /Zc:forScope /Gd /analyze-
链接器选项: /INCREMENTAL:NO "kernel32.lib" "user32.lib" "gdi32.lib" "winspool.lib" "comdlg32.lib" "advapi32.lib" "shell32.lib" "ole32.lib" "oleaut32.lib" "uuid.lib" "odbc32.lib" "odbccp32.lib" /ALLOWISOLATION /MANIFESTUAC:"level='asInvoker' uiAccess='false'" /SUBSYSTEM:CONSOLE /OPT:REF /OPT:ICF /LTCG /TLBID:1 /DYNAMICBASE /NXCOMPAT /MACHINE:X86 /ERRORREPORT:QUEUE
a.e<b.e相比,j%10可能需要更长的时间。你可以尝试将j%10替换为类似于j%16的东西,并用&15替换它来重新进行测试吗? - Kamyar Souri