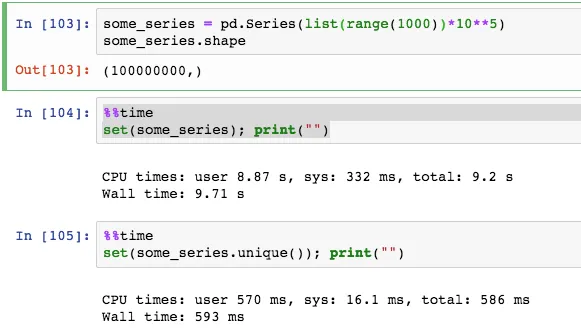
我有一个从 Kaggle 的 San Francisco Salaries 中提取的数据框,链接在这里 https://www.kaggle.com/kaggle/sf-salaries ,我想创建一个列值的集合,例如 'Status'。
这是我尝试过的代码,但它带来的是所有记录的列表,而不是集合(sf 是我给数据框命名的方式)。
这是我尝试过的代码,但它带来的是所有记录的列表,而不是集合(sf 是我给数据框命名的方式)。
a=set(sf['Status'])
print a
a是一个列表? - tacaswell