我是一名编程老师,想写一个脚本来检测 C/C++/Python 文件中的重复次数。我想可以把任何文件都看作纯文本。
此脚本的输出将是重复出现的相似序列数量。最终,我只对 DRY 指标感兴趣(代码满足 DRY 原则的程度)。
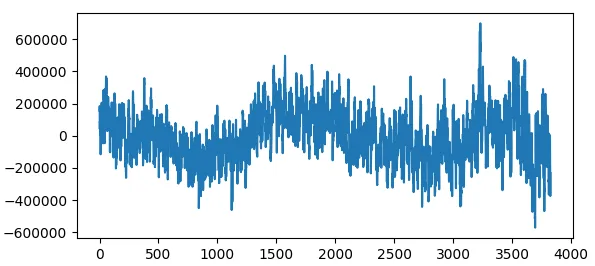
我尝试过简单的自相关,但很难找到合适的阈值。
u = open("find.c").read()
v = [ord(x) for x in u]
y = np.correlate(v, v, mode="same")
y = y[: int(len(y) / 2)]
x = range(len(y))
z = np.polyval(np.polyfit(x, y, 3), x)
f = (y - z)[: -5]
plt.plot(f)
plt.show();
我正在研究不同的策略...... 我还尝试比较每行、每组2行、每组3行之间的相似性......
import difflib
import numpy as np
lines = open("b.txt").readlines()
lines = [line.strip() for line in lines]
n = 3
d = []
for i in range(len(lines)):
a = lines[i:i+n]
for j in range(len(lines)):
b = lines[j:j+n]
if i == j: continue # skip same line
group_size = np.sum([len(x) for x in a])
if group_size < 5: continue # skip short lines
ratio = 0
for u, v in zip(a, b):
r = difflib.SequenceMatcher(None, u, v).ratio()
ratio += r if r > 0.7 else 0
d.append(ratio)
dry = sum(d) / len(lines)
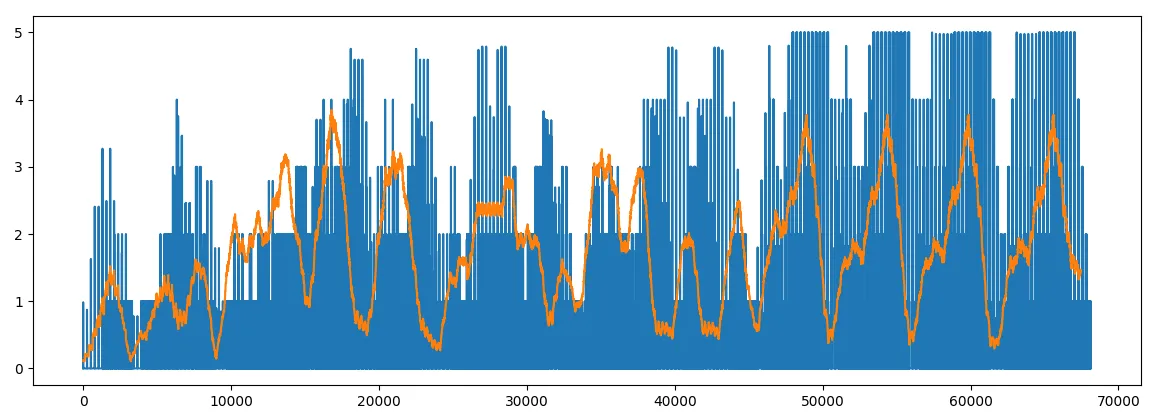
在下面,我们可以一眼看出一些重复的内容:
w = int(len(d) / 100)
e = np.convolve(d, np.ones(w), "valid") / w * 10
plt.plot(range(len(d)), d, range(len(e)), e)
plt.show()
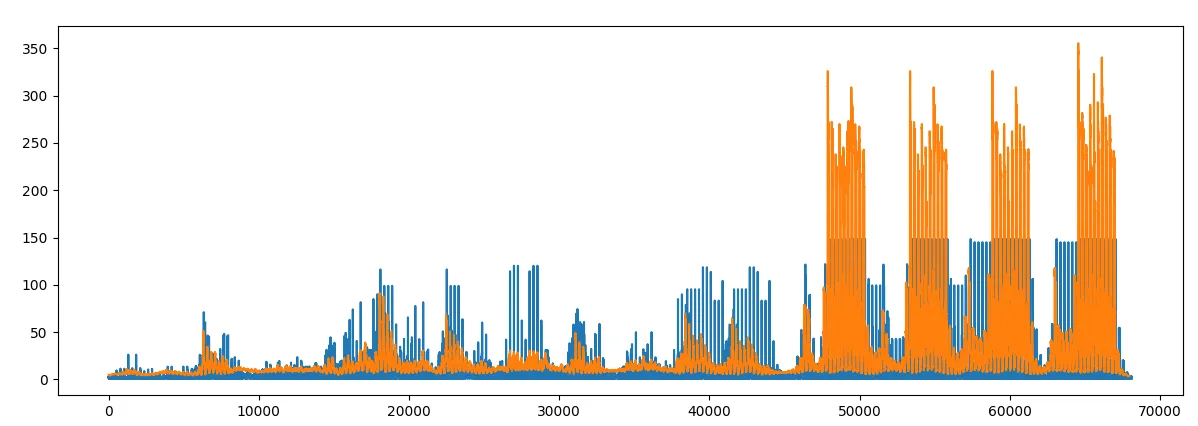
为什么不使用:
d = np.exp(np.array(d))
因此,difflib 模块看起来很有前途,SequenceMatcher 做了一些魔法(Levenshtein?),但我还需要一些魔法常数(0.7)... 然而,这段代码是 > O(n^2),对于长文件运行非常慢。
有趣的是,通过细心的观察,重复的次数可以很容易地被识别出来(很抱歉将这位学生的代码作为好坏示例):
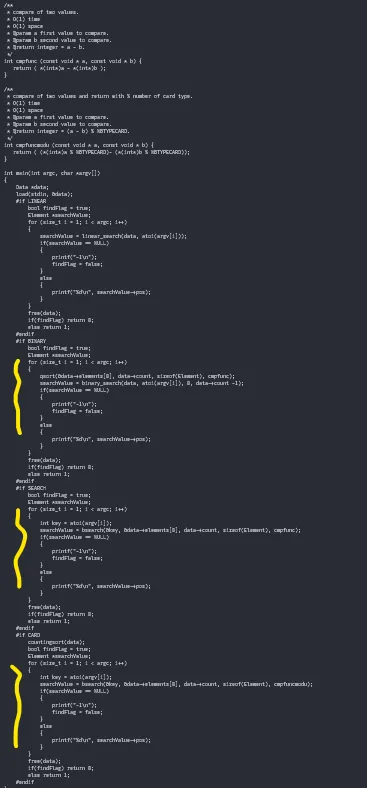
我相信肯定有更聪明的解决方案。
有什么提示吗?