我目前正在自学C++,并且对于push_back()和emplace_back()在底层是如何工作很好奇。我一直认为当你尝试构造并将一个大对象推入容器(如vector)的末尾时,emplace_back()更快。
假设我有一个Student对象,我想将其附加到一个包含Student的向量的末尾。
struct Student {
string name;
int student_ID;
double GPA;
string favorite_food;
string favorite_prof;
int hours_slept;
int birthyear;
Student(string name_in, int ID_in, double GPA_in, string food_in,
string prof_in, int sleep_in, int birthyear_in) :
/* initialize member variables */ { }
};
假设我调用push_back()并推送一个Student对象到向量的末尾:
vector<Student> vec;
vec.push_back(Student("Bob", 123456, 3.89, "pizza", "Smith", 7, 1997));
我的理解是push_back在向量外部创建一个Student对象实例,然后将其移至向量的末尾。
示意图: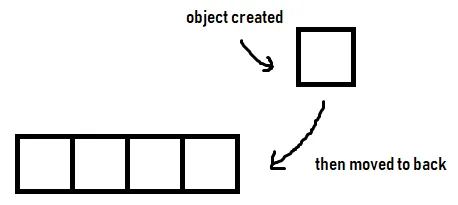
我也可以选择使用emplace而不是push:
vector<Student> vec;
vec.emplace_back("Bob", 123456, 3.89, "pizza", "Smith", 7, 1997);
我的理解是,学生对象在向量的最后构建,因此不需要移动。
图表: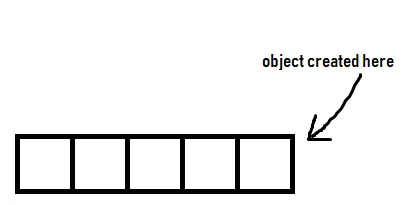
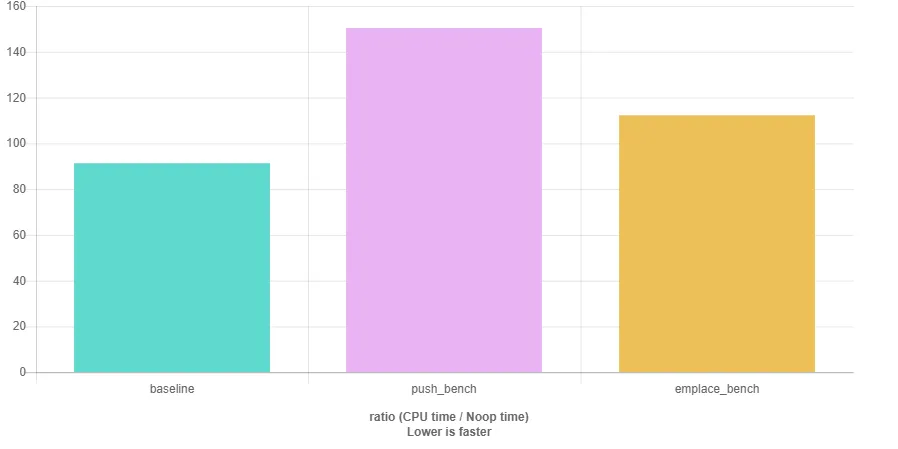
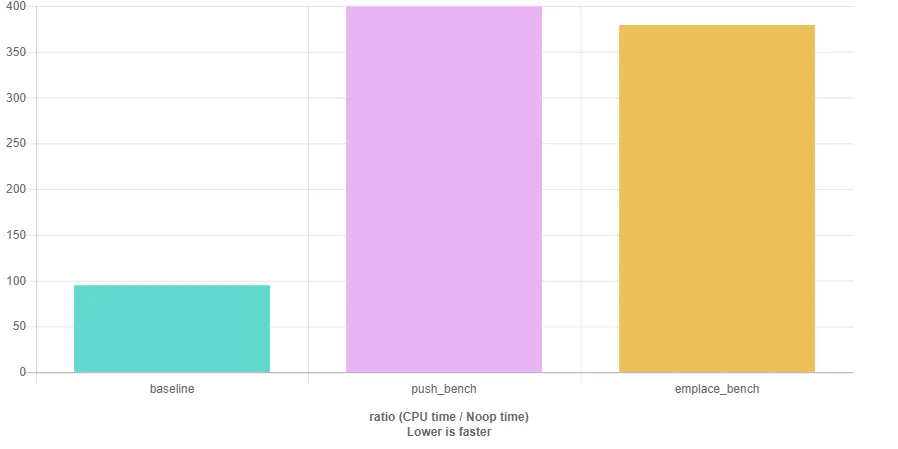
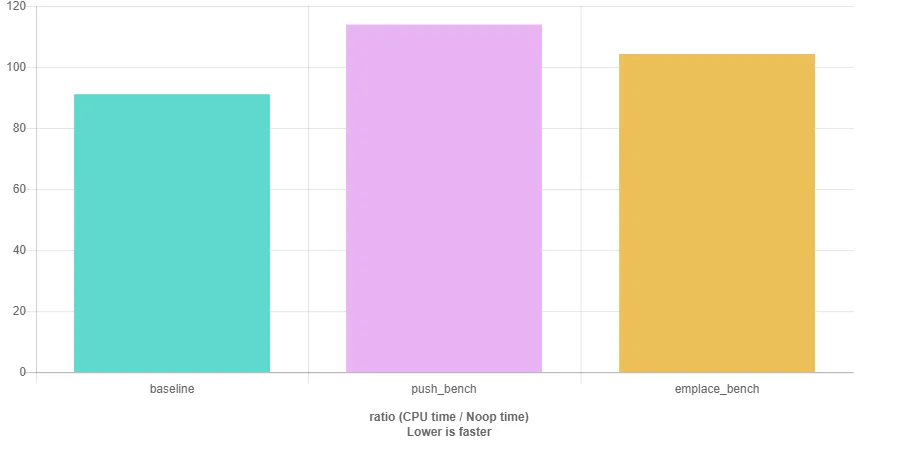
因此,调用 emplace 的速度会更快,特别是当添加许多学生对象时。然而,当我计时这两个代码版本时:
for (int i = 0; i < 10000000; ++i) {
vec.push_back(Student("Bob", 123456, 3.89, "pizza", "Smith", 7, 1997));
}
和
for (int i = 0; i < 10000000; ++i) {
vec.emplace_back("Bob", 123456, 3.89, "pizza", "Smith", 7, 1997);
}
我本以为使用emplace_back会更快,因为不需要复制大型的Student对象。然而奇怪的是,在多次尝试后,emplace_back版本实际上变得更慢了。我还尝试插入10000000个Student对象,其中构造函数接受引用,并且push_back()和emplace_back()中的参数存储在变量中。但这也行不通,因为emplace仍然更慢。
我已经检查过确保在两种情况下都插入相同数量的对象。时间差异并不太大,但emplace比push_back慢几秒钟。
我的push_back()和emplace_back()的理解有问题吗?非常感谢您的时间!
如请求所示,以下是代码。我正在使用g++编译器。
Push back:
struct Student {
string name;
int student_ID;
double GPA;
string favorite_food;
string favorite_prof;
int hours_slept;
int birthyear;
Student(string name_in, int ID_in, double GPA_in, string food_in,
string prof_in, int sleep_in, int birthyear_in) :
name(name_in), student_ID(ID_in), GPA(GPA_in),
favorite_food(food_in), favorite_prof(prof_in),
hours_slept(sleep_in), birthyear(birthyear_in) {}
};
int main() {
vector<Student> vec;
vec.reserve(10000000);
for (int i = 0; i < 10000000; ++i)
vec.push_back(Student("Bob", 123456, 3.89, "pizza", "Smith", 7, 1997));
return 0;
}
插入到末尾:
struct Student {
string name;
int student_ID;
double GPA;
string favorite_food;
string favorite_prof;
int hours_slept;
int birthyear;
Student(string name_in, int ID_in, double GPA_in, string food_in,
string prof_in, int sleep_in, int birthyear_in) :
name(name_in), student_ID(ID_in), GPA(GPA_in),
favorite_food(food_in), favorite_prof(prof_in),
hours_slept(sleep_in), birthyear(birthyear_in) {}
};
int main() {
vector<Student> vec;
vec.reserve(10000000);
for (int i = 0; i < 10000000; ++i)
vec.emplace_back("Bob", 123456, 3.89, "pizza", "Smith", 7, 1997);
return 0;
}
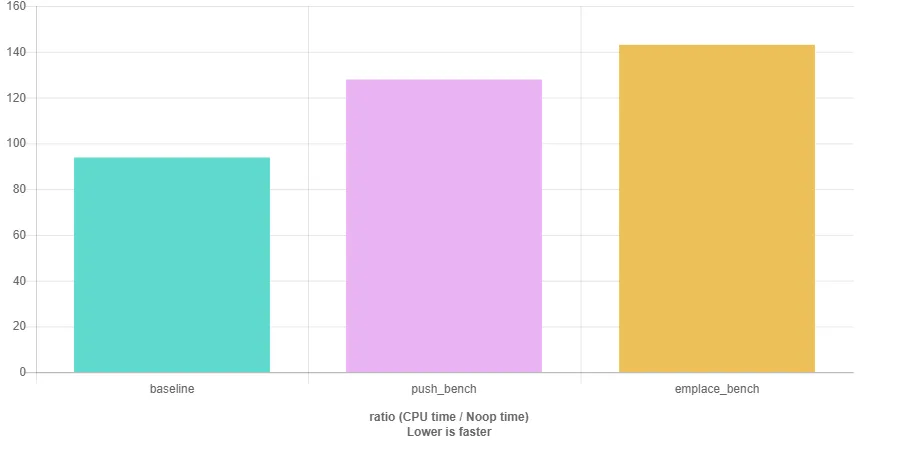
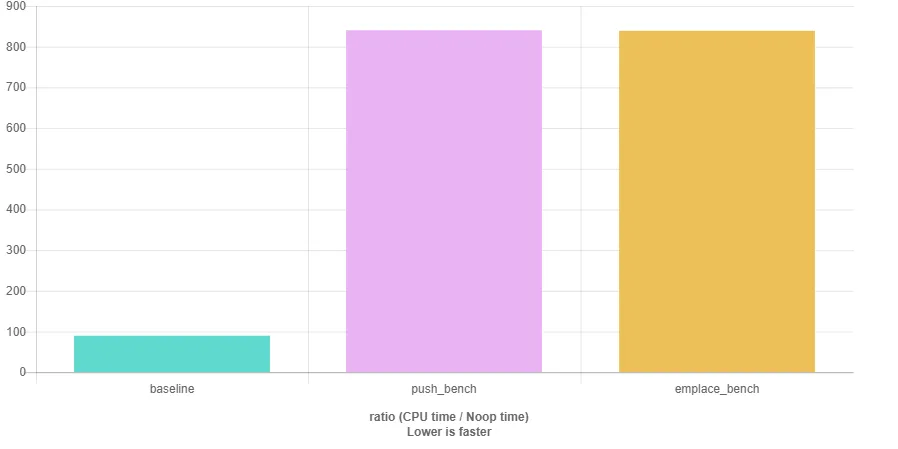
emplace_back传递7个参数,而只需要向push_back传递一个参数。 - Bo Persson