我正在尝试制作一个简单的GANs来从MNIST数据集中生成数字。但是当我到达训练阶段(这是自定义的)时,我收到了这个令人讨厌的警告,我怀疑它是导致训练不像我习惯的那样的原因。
请记住,所有这些都在tensorflow 2.0中,并使用默认的急切执行。
获取数据(不是太重要)
(train_images,train_labels),(test_images,test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
train_dataset = tf.data.Dataset.from_tensor_slices((train_images,train_labels)).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
生成器模型(批量正则化在此处实现)
def make_generator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
判别模型(可能不那么重要)
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same'))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1))
return model
实例化模型(可能不太重要)
generator = make_generator_model()
discriminator = make_discriminator_model()
定义损失(也许生成器的损失很重要,因为那是梯度来自的地方)
def generator_loss(generated_output):
return tf.nn.sigmoid_cross_entropy_with_logits(labels = tf.ones_like(generated_output), logits = generated_output)
def discriminator_loss(real_output, generated_output):
# [1,1,...,1] with real output since it is true and we want our generated examples to look like it
real_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(real_output), logits=real_output)
# [0,0,...,0] with generated images since they are fake
generated_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.zeros_like(generated_output), logits=generated_output)
total_loss = real_loss + generated_loss
return total_loss
优化器的制作(可能不是很重要)
generator_optimizer = tf.optimizers.Adam(1e-4)
discriminator_optimizer = tf.optimizers.Adam(1e-4)
为生成器添加随机噪声(可能不重要)
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# We'll re-use this random vector used to seed the generator so
# it will be easier to see the improvement over time.
random_vector_for_generation = tf.random.normal([num_examples_to_generate,
noise_dim])
单个训练步骤(这是我遇到错误的地方)
def train_step(images):
# generating noise from a normal distribution
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images[0], training=True)
generated_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(generated_output)
disc_loss = discriminator_loss(real_output, generated_output)
This line >>>>>
gradients_of_generator = gen_tape.gradient(gen_loss, generator.variables)
<<<<< This line
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.variables))
完整的训练过程(除了调用train_step之外并不重要)
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for images in dataset:
train_step(images)
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
random_vector_for_generation)
# saving (checkpoint) the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time taken for epoch {} is {} sec'.format(epoch + 1,
time.time()-start))
# generating after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
random_vector_for_generation)
开始培训
train(train_dataset, EPOCHS)
我得到的错误如下:
W0330 19:42:57.366302 4738405824 optimizer_v2.py:928] Gradients does
not exist for variables ['batch_normalization_v2_54/moving_mean:0',
'batch_normalization_v2_54/moving_variance:0',
'batch_normalization_v2_55/moving_mean:0',
'batch_normalization_v2_55/moving_variance:0',
'batch_normalization_v2_56/moving_mean:0',
'batch_normalization_v2_56/moving_variance:0'] when minimizing the
loss.
我从生成器中获得了以下图像:
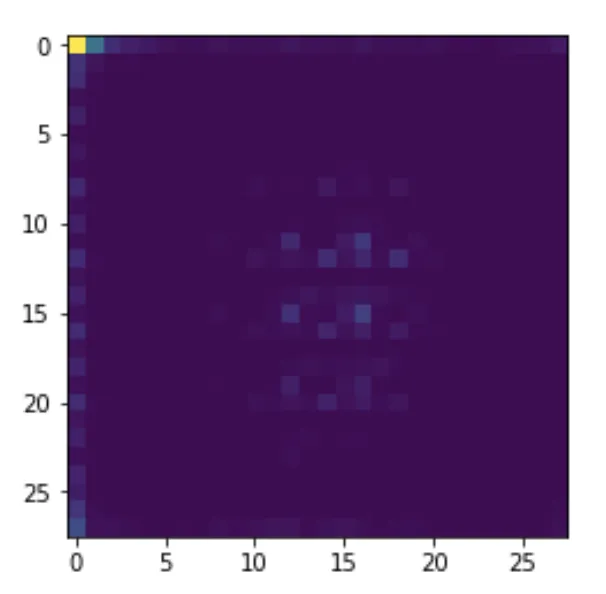
如果没有标准化,这就是我所期望的结果。由于存在极端值,所有值都会聚集到一角。