在模型中使用的变量名称和预测过程中使用的变量名称需要更加仔细地匹配。您遇到的错误是因为predict函数中数据框中的名称与模型中术语的名称不匹配,因此您实际上并未预测新值。问题在于predict实际上是从数据框中获取数据。
model.frame(~cars$dist, data.frame(dist=c.x))
因为您在公式中明确使用了cars$dist,所以没有任何“自由”符号会从您的新数据参数中提取。与此相比,与之前的结果进行对比:
model.frame(~dist, data.frame(dist=c.x))
这次,
dist不再特定地绑定到
cars变量上,而可以在新数据框的上下文中“解决”。
此外,您希望确保将
dist值保持在相同的比例尺上。例如。
c.model <- glm(speed~dist, data=cars, family=gaussian)
summary(c.model)
c.x <- seq(min(cars$dist),max(cars$dist),length.out=101)
c.y <- predict.glm(c.model,data.frame(dist=c.x), type="response")
plot(speed~dist, cars)
lines(c.x,c.y)
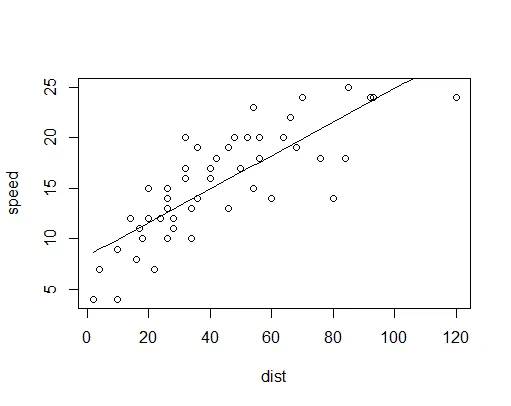
我们预测的范围是观察值的范围,而不是0-1,因为没有距离值真正小于1。
c.x的长度为101,而c.y的长度为50。 - Steven