这应该就可以了。我在电脑上有一个HTML文件夹(来自SO的随机样本),我已经将它们制作成语料库,然后创建了文档-词项矩阵,并进行了一些简单的文本挖掘任务。
setwd("C:/Downloads/html")
html <- list.files(pattern="\\.(htm|html)$")
library(tm)
library(RCurl)
library(XML)
writeChar(con="htmlToText.R", (getURL(ssl.verifypeer = FALSE, "https://raw.github.com/tonybreyal/Blog-Reference-Functions/master/R/htmlToText/htmlToText.R")))
source("htmlToText.R")
html2txt <- lapply(html, htmlToText)
html2txtclean <- sapply(html2txt, function(x) iconv(x, "latin1", "ASCII", sub=""))
corpus <- Corpus(VectorSource(html2txtclean))
skipWords <- function(x) removeWords(x, stopwords("english"))
funcs <- list(tolower, removePunctuation, removeNumbers, stripWhitespace, skipWords)
a <- tm_map(a, PlainTextDocument)
a <- tm_map(corpus, FUN = tm_reduce, tmFuns = funcs)
a.dtm1 <- TermDocumentMatrix(a, control = list(wordLengths = c(3,10)))
newstopwords <- findFreqTerms(a.dtm1, lowfreq=10)
a.dtm2 <- a.dtm1[!(a.dtm1$dimnames$Terms) %in% newstopwords,]
inspect(a.dtm2)
a.dtm3 <- removeSparseTerms(a.dtm2, sparse=0.7)
a.dtm.df <- as.data.frame(inspect(a.dtm3))
a.dtm.df.scale <- scale(a.dtm.df)
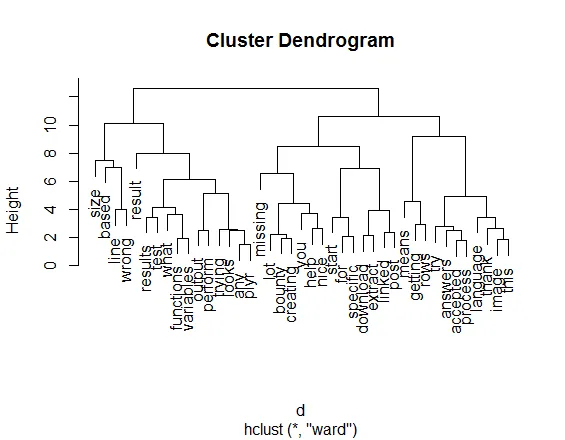
d <- dist(a.dtm.df.scale, method = "euclidean")
fit <- hclust(d, method="ward")
plot(fit)
library(wordcloud)
library(RColorBrewer)
m = as.matrix(t(a.dtm1))
word_freqs = sort(colSums(m), decreasing=TRUE)
dm = data.frame(word=names(word_freqs), freq=word_freqs)
wordcloud(dm$word, dm$freq, random.order=FALSE, colors=brewer.pal(8, "Dark2"))

C:\ test- Brandon BertelsenCorpus和DirSource命令属于哪个软件包? - CHP