在我的数据集中,我有一个二进制的目标变量(0或1)和8个特征:nchar,rtc,Tmean,week_day,hour,ntags,nlinks和nex。week_day是一个因子变量,而其他变量是数值型的。我试图构建一个决策树分类器:
library(caTools)
set.seed(123)
split = sample.split(dataset$Target, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[-c(2,4)] = scale(training_set[-c(2,4)])
test_set[-c(2,4)] = scale(test_set[-c(2,4)])
# Fitting Decision Tree Classification to the Training set
# install.packages('rpart')
library(rpart)
classifier = rpart(formula = Target ~ .,
data = training_set)
# Predicting the Test set results
y_pred = predict(classifier, newdata = test_set[-2], type = 'class')
# Making the Confusion Matrix
cm = table(test_set[, 2], y_pred)
plot(classifier, uniform=TRUE,margin=0.2)
绘图结果如下:
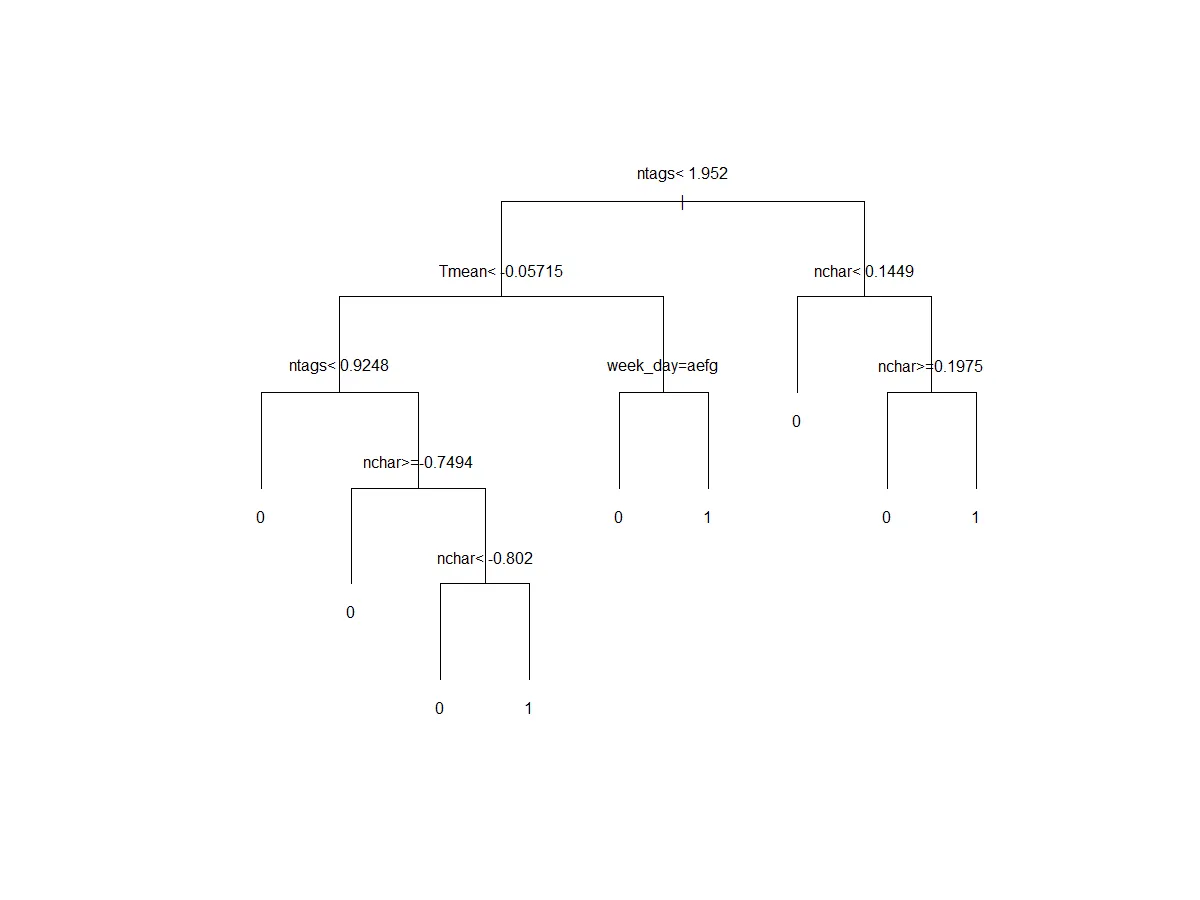
我有三个问题不知道答案:
- 为什么在图表中有些变量缺失?(例如,
rtc) week_day中的aefg是什么意思?- 是否有一种方法可以描述不同类别(
Target变量的 0 和 1)之间的差异?例如:在Target=1中,我们有所有具有nchar>0.19和ntags>1.9的行,等等。