C#中的异常有多昂贵?只要堆栈不太深,它们似乎并不是非常昂贵,但我读到了一些相互矛盾的报告。
是否有未被反驳的明确报告?
static void Main(string[] args)
{
int iterations = 1000000;
Console.WriteLine("Starting " + iterations.ToString() + " iterations...\n");
var stopwatch = new Stopwatch();
// Test exceptions
stopwatch.Reset();
stopwatch.Start();
for (int i = 1; i <= iterations; i++)
{
try
{
TestExceptions();
}
catch (Exception)
{
// Do nothing
}
}
stopwatch.Stop();
Console.WriteLine("Exceptions: " + stopwatch.ElapsedMilliseconds.ToString() + " ms");
// Test return codes
stopwatch.Reset();
stopwatch.Start();
int retcode;
for (int i = 1; i <= iterations; i++)
{
retcode = TestReturnCodes();
if (retcode == 1)
{
// Do nothing
}
}
stopwatch.Stop();
Console.WriteLine("Return codes: " + stopwatch.ElapsedMilliseconds.ToString() + " ms");
Console.WriteLine("\nFinished.");
Console.ReadKey();
}
static void TestExceptions()
{
throw new Exception("Failed");
}
static int TestReturnCodes()
{
return 1;
}
assert,而错误处理则应通过错误代码完成。@mpen - Konrad我认为如果异常的表现影响到您的应用程序,那么您抛出的异常太多了。异常应该是用于特殊情况而不是常规错误处理。
话虽如此,我的记忆中异常处理的本质是从堆栈底部开始查找与抛出的异常类型匹配的catch语句。因此性能将受到您距离catch语句的深度以及您拥有的catch语句数量的影响。
在我的情况下,异常非常昂贵。我重写了这个代码:
public BlockTemplate this[int x,int y, int z]
{
get
{
try
{
return Data.BlockTemplate[World[Center.X + x, Center.Y + y, Center.Z + z]];
}
catch(IndexOutOfRangeException e)
{
return Data.BlockTemplate[BlockType.Air];
}
}
}
转化为如下内容:
public BlockTemplate this[int x,int y, int z]
{
get
{
int ix = Center.X + x;
int iy = Center.Y + y;
int iz = Center.Z + z;
if (ix < 0 || ix >= World.GetLength(0)
|| iy < 0 || iy >= World.GetLength(1)
|| iz < 0 || iz >= World.GetLength(2))
return Data.BlockTemplate[BlockType.Air];
return Data.BlockTemplate[World[ix, iy, iz]];
}
}
我注意到速度提高了约30秒。这个函数在启动时至少被调用32,000次。虽然代码的意图不是很明确,但节省的成本非常巨大。
我自己进行了测量,以查明异常的影响有多严重。我并没有试图测量抛出/捕获异常的绝对时间,而是更关心在每次循环中抛出异常会使循环变得多慢。测量代码如下:
for(; ; ) {
iValue = Level1(iValue);
lCounter += 1;
if(DateTime.Now >= sFinish)
break;
}
对比。
for(; ; ) {
try {
iValue = Level3Throw(iValue);
}
catch(InvalidOperationException) {
iValue += 3;
}
lCounter += 1;
if(DateTime.Now >= sFinish)
break;
}
C#中的基本异常对象相当轻量级;通常是封装InnerException时,当对象树变得太深时才会变得沉重。
至于确定性报告,我不知道有没有,虽然进行内存消耗和速度的初步dotTrace分析(或任何其他分析器)将非常容易。
以下是我的个人经验:
我正在开发一个程序,用Newtonsoft (Json.NET)解析JSON文件并从中提取数据。
我对此进行了改写:
try
{
name = rawPropWithChildren.Value["title"].ToString();
}
catch(System.NullReferenceException)
{
name = rawPropWithChildren.Name;
}
改为如下:
if(rawPropWithChildren.Value["title"] == null)
{
name = rawPropWithChildren.Name;
}
else
{
name = rawPropWithChildren.Value["title"].ToString();
}
选项1,包含异常。 38.50秒
选项2,不包含异常。 06.48秒
简而言之;
例外情况往往比任何连接的服务或数据调用快上几个数量级,因此避免使用它们很可能无法提供实际的好处,而这些例外情况提供了改进的信息和控制流。
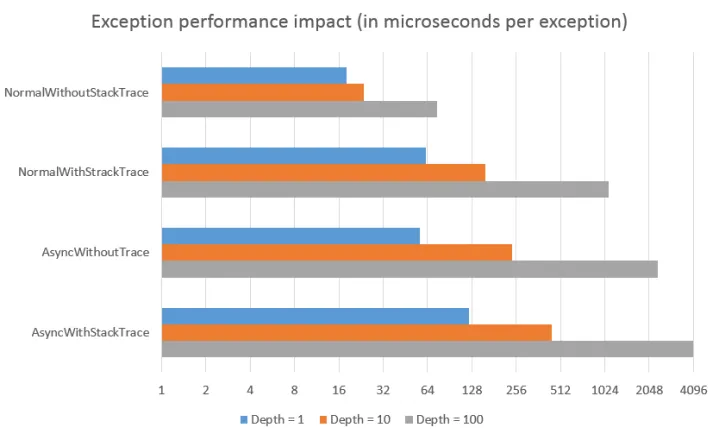 来自这篇文章的图片和他发布的测试代码:.Net exceptions performance
来自这篇文章的图片和他发布的测试代码:.Net exceptions performance
你通常会得到你所付出的代价吗? 大多数时候是的。
更详细的解释:
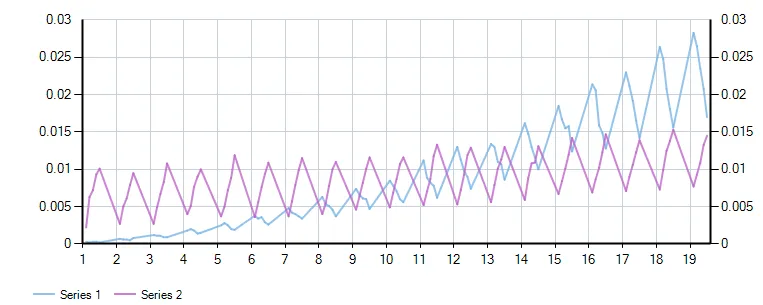
void Main()
{
var loopResults = new List<Results>();
var exceptionResults = new List<Results>();
var totalRuns = 10000;
for (var colCount = 1; colCount < 20; colCount++)
{
using (var conn = new SqlConnection(@"Data Source=(localdb)\MSSQLLocalDb;Initial Catalog=master;Integrated Security=True;"))
{
conn.Open();
//create a dummy table where we can control the total columns
var columns = String.Join(",",
(new int[colCount]).Select((item, i) => $"'{i}' as col{i}")
);
var sql = $"select {columns} into #dummyTable";
var cmd = new SqlCommand(sql,conn);
cmd.ExecuteNonQuery();
var cmd2 = new SqlCommand("select * from #dummyTable", conn);
var reader = cmd2.ExecuteReader();
reader.Read();
Func<Func<IDataRecord, String, Boolean>, List<Results>> test = funcToTest =>
{
var results = new List<Results>();
Random r = new Random();
for (var faultRate = 0.1; faultRate <= 0.5; faultRate += 0.1)
{
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
var faultCount=0;
for (var testRun = 0; testRun < totalRuns; testRun++)
{
if (r.NextDouble() <= faultRate)
{
faultCount++;
if(funcToTest(reader, "colDNE"))
throw new ApplicationException("Should have thrown false");
}
else
{
for (var col = 0; col < colCount; col++)
{
if(!funcToTest(reader, $"col{col}"))
throw new ApplicationException("Should have thrown true");
}
}
}
stopwatch.Stop();
results.Add(new UserQuery.Results{
ColumnCount = colCount,
TargetNotFoundRate = faultRate,
NotFoundRate = faultCount * 1.0f / totalRuns,
TotalTime=stopwatch.Elapsed
});
}
return results;
};
loopResults.AddRange(test(HasColumnLoop));
exceptionResults.AddRange(test(HasColumnException));
}
}
"Loop".Dump();
loopResults.Dump();
"Exception".Dump();
exceptionResults.Dump();
var combinedResults = loopResults.Join(exceptionResults,l => l.ResultKey, e=> e.ResultKey, (l, e) => new{ResultKey = l.ResultKey, LoopResult=l.TotalTime, ExceptionResult=e.TotalTime});
combinedResults.Dump();
combinedResults
.Chart(r => r.ResultKey, r => r.LoopResult.Milliseconds * 1.0 / totalRuns, LINQPad.Util.SeriesType.Line)
.AddYSeries(r => r.ExceptionResult.Milliseconds * 1.0 / totalRuns, LINQPad.Util.SeriesType.Line)
.Dump();
}
public static bool HasColumnLoop(IDataRecord dr, string columnName)
{
for (int i = 0; i < dr.FieldCount; i++)
{
if (dr.GetName(i).Equals(columnName, StringComparison.InvariantCultureIgnoreCase))
return true;
}
return false;
}
public static bool HasColumnException(IDataRecord r, string columnName)
{
try
{
return r.GetOrdinal(columnName) >= 0;
}
catch (IndexOutOfRangeException)
{
return false;
}
}
public class Results
{
public double NotFoundRate { get; set; }
public double TargetNotFoundRate { get; set; }
public int ColumnCount { get; set; }
public double ResultKey {get => ColumnCount + TargetNotFoundRate;}
public TimeSpan TotalTime { get; set; }
}
最近我在一个求和循环中测量了C#异常(抛出和捕获),每次加法都会引发算术溢出。算术溢出的抛出和捕获大约为8.5微秒= 117千例外/秒,在四核笔记本电脑上。
异常是昂贵的,但在选择异常和返回代码之间时,还有更多需要考虑的因素。
从历史上看,争论的焦点是:异常确保代码被强制处理情况,而返回代码可以被忽略。我从未支持这些论点,因为没有程序员会想要故意忽略并破坏他们的代码 - 尤其是一个好的测试团队/或者一个编写良好的测试用例肯定不会忽略返回代码。
从现代编程实践的角度来看,管理异常需要考虑到它们的成本和可行性。
由于大多数前端将与抛出异常的API断开连接。例如,使用REST API的移动应用程序。同样的API也可以用于基于Angular的Web前端。
任何一种情况都更喜欢使用返回代码而不是异常。
现今,黑客们会随意尝试破解所有网络工具。在这种情况下,如果他们一直攻击您的应用程序登录API,并且该应用程序不断抛出异常,那么您每天将处理成千上万个异常。当然,许多人会说防火墙会处理此类攻击。但是,并非所有人都愿意花钱管理专用防火墙或昂贵的反垃圾邮件服务。更好的做法是使您的代码准备好应对这些情况。