我真的不明白Hadoop为什么比关系型数据库更好地扩展。可以有人详细解释一下吗?这与底层数据结构和算法有关吗?
4个回答
6
RDBMS在处理TB和PB级别的大数据时存在挑战。即使您拥有独立/廉价磁盘阵列(RAID)和数据分片,也无法很好地扩展到大量数据。您需要非常昂贵的硬件。
编辑:为了回答为什么RDBMS无法扩展,请看 RBDMS开销。
记录。组装日志记录并跟踪所有更改数据库结构会降低性能。如果不需要可恢复性或者可通过其他手段提供可恢复性(例如网络上的其他站点),则可能不需要记录。
锁定。传统的两阶段锁定会带来相当大的开销,因为所有对数据库结构的访问都受到单独实体锁管理器的控制。
闩锁。在多线程数据库中,许多数据结构必须被闩锁才能被访问。去除此功能并采用单线程方法会对性能产生明显影响。 缓存管理。主内存数据库系统不需要通过缓冲池访问页面,每次记录访问都可以消除一个间接层。 Hadoop如何处理?
Hadoop是一个免费的基于Java的编程框架,支持在分布式计算环境中处理大型数据集,可以运行在普通硬件上。它适用于存储和检索大量数据。
这种可扩展性和效率是通过Hadoop实现存储机制(HDFS)和处理作业(YARN Map reduce jobs)来实现的。除了可扩展性外,Hadoop还提供了存储数据的高可用性。
可扩展性、高可用性、处理大量数据(结构化数据、非结构化数据、半结构化数据)以及灵活性是Hadoop成功的关键。
数据存储在数千个节点上,处理通常通过Map Reduce作业在数据存储的节点上完成。处理前的数据本地性是Hadoop成功的关键领域之一。
这是通过Name Node、Data Node和Resource Manager实现的。
为了理解Hadoop是如何实现这一点的,您必须访问以下链接:HDFS架构,YARN架构和HDFS联邦。
尽管关系型数据库管理系统(RDBMS)适用于对千兆字节的数据进行多次写入/读取/更新和一致性ACID事务,但不适用于处理太多字节和拍字节的数据。CAP理论中具有一致性、可用性和分区属性的NoSQL在某些用例中表现良好。
但是,Hadoop并不适用于具有ACID属性的实时交易支持。它适用于批处理的商业智能报告-"只写一次,多次读取"的范例。
来自slideshare.net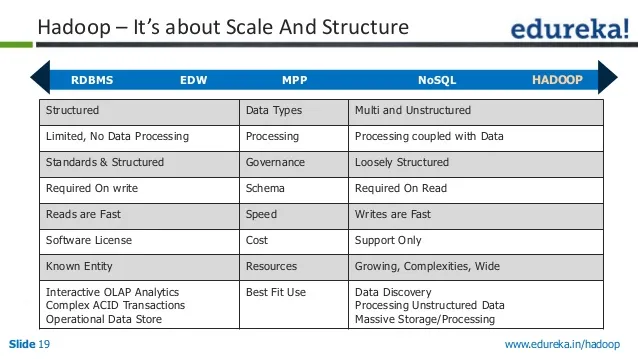 。
。
编辑:为了回答为什么RDBMS无法扩展,请看 RBDMS开销。
记录。组装日志记录并跟踪所有更改数据库结构会降低性能。如果不需要可恢复性或者可通过其他手段提供可恢复性(例如网络上的其他站点),则可能不需要记录。
锁定。传统的两阶段锁定会带来相当大的开销,因为所有对数据库结构的访问都受到单独实体锁管理器的控制。
闩锁。在多线程数据库中,许多数据结构必须被闩锁才能被访问。去除此功能并采用单线程方法会对性能产生明显影响。 缓存管理。主内存数据库系统不需要通过缓冲池访问页面,每次记录访问都可以消除一个间接层。 Hadoop如何处理?
Hadoop是一个免费的基于Java的编程框架,支持在分布式计算环境中处理大型数据集,可以运行在普通硬件上。它适用于存储和检索大量数据。
这种可扩展性和效率是通过Hadoop实现存储机制(HDFS)和处理作业(YARN Map reduce jobs)来实现的。除了可扩展性外,Hadoop还提供了存储数据的高可用性。
可扩展性、高可用性、处理大量数据(结构化数据、非结构化数据、半结构化数据)以及灵活性是Hadoop成功的关键。
数据存储在数千个节点上,处理通常通过Map Reduce作业在数据存储的节点上完成。处理前的数据本地性是Hadoop成功的关键领域之一。
这是通过Name Node、Data Node和Resource Manager实现的。
为了理解Hadoop是如何实现这一点的,您必须访问以下链接:HDFS架构,YARN架构和HDFS联邦。
尽管关系型数据库管理系统(RDBMS)适用于对千兆字节的数据进行多次写入/读取/更新和一致性ACID事务,但不适用于处理太多字节和拍字节的数据。CAP理论中具有一致性、可用性和分区属性的NoSQL在某些用例中表现良好。
但是,Hadoop并不适用于具有ACID属性的实时交易支持。它适用于批处理的商业智能报告-"只写一次,多次读取"的范例。
来自slideshare.net
。
请看另一个相关的SE问题:
- Ravindra babu
7
我同意,数据本地性是Hadoop的一个关键特性,其中代码移到数据所在的位置,而数据不通过网络流动进行处理。你上面提到的RAID问题,它是否与RDBMS中的集群能力有关呢?请原谅,我不是一个数据库专家。如果这是在RDBMS世界中实现集群的一种方法,那么为什么需要昂贵的硬件来提高性能的核心原因是什么呢? - redeemed
RAID + 数据分片是关系型数据库的可扩展性方式,但并不十分成功。它非常昂贵且成功率有限。 - Ravindra babu
谢谢。但我的问题是关系型数据库不可扩展性背后的根本原因是什么。 - redeemed
关系型数据库可以处理千兆字节的数据,而Hadoop提供了支持太/拍字节数据的框架。MapReduce是实现这一目标的关键,因为它在具有数据本地性的数据节点上进行处理。 - Ravindra babu
关系型数据库不支持像Hadoop这样的框架,可以在2000多个数据节点上进行处理,仍然可以通过集中控制器发布结果。 - Ravindra babu
显示剩余2条评论
1
首先,Hadoop不是数据库的替代品。
关系型数据库(RDBMS)是纵向扩展,而Hadoop是横向扩展。
这意味着,为了将RDBMS扩展两倍,您需要具有双倍的内存、双倍的存储和双倍的CPU硬件。这非常昂贵且有限制。例如,没有一台服务器拥有10TB的RAM。使用Hadoop就不同了,您不需要昂贵的边缘技术,而是可以使用多个普通服务器一起工作,模拟一个更大的服务器(有一些限制)。您可以拥有一个分布在多个节点上的10TB RAM集群。
另一个优点是,与其购买新的更强大的服务器并放弃旧服务器,分布式系统只需要将新节点添加到集群中即可进行扩展。
- RojoSam
0
我对上面的描述唯一的问题是并行RDBMS需要昂贵的硬件。Teridata和Netezza需要特殊的硬件。Greenplum和Vertica可以放在普通硬件上。(现在我承认我有偏见,像其他人一样。)我见过Greenplum每天扫描PB级别的信息。(沃尔玛最近达到了2.5 PB。)我处理过Hawq和Impala。它们都需要大约30%的额外硬件来处理结构化数据。Hbase效率较低。
没有魔法银勺子。我的经验是结构化和非结构化都有其用处。Hadoop非常适合摄取大量数据并仅扫描几次。我们将其用作我们的加载程序的一部分。RDBMS非常适合使用高度复杂的查询多次扫描相同的数据。
您始终必须对数据进行结构化以利用它。这种结构化需要花费时间。您可以在将其放入RDBMS之前或在查询时进行结构化。
- Brian France
-1
在关系型数据库中,数据是有结构的,而且通常是索引的。检索任何特定“第n列”的数据需要加载整个数据库,然后选择“第n列”。
而在Hadoop中,比如Hive,我们仅从整个数据集中加载特定的列。此外,数据加载也是通过Map reduce程序以分布式结构完成的,这可以减少总时间。
因此,使用Hadoop及其工具有两个优点。
而在Hadoop中,比如Hive,我们仅从整个数据集中加载特定的列。此外,数据加载也是通过Map reduce程序以分布式结构完成的,这可以减少总时间。
因此,使用Hadoop及其工具有两个优点。
- Storm
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接