这个问题适用于所有的NoSQL专家,尤其是mongoDB专家。我最初为一个项目设计了一个关系型数据库,但客户想要我们使用能够轻松扩展的数据库。为了实现这一点,我们决定使用mongoDB。近日,我在将我的关系模型映射到NoSQL时遇到了一些困难。我有一个用户表,它与许多其他表存在多对多的关系,如下图所示:
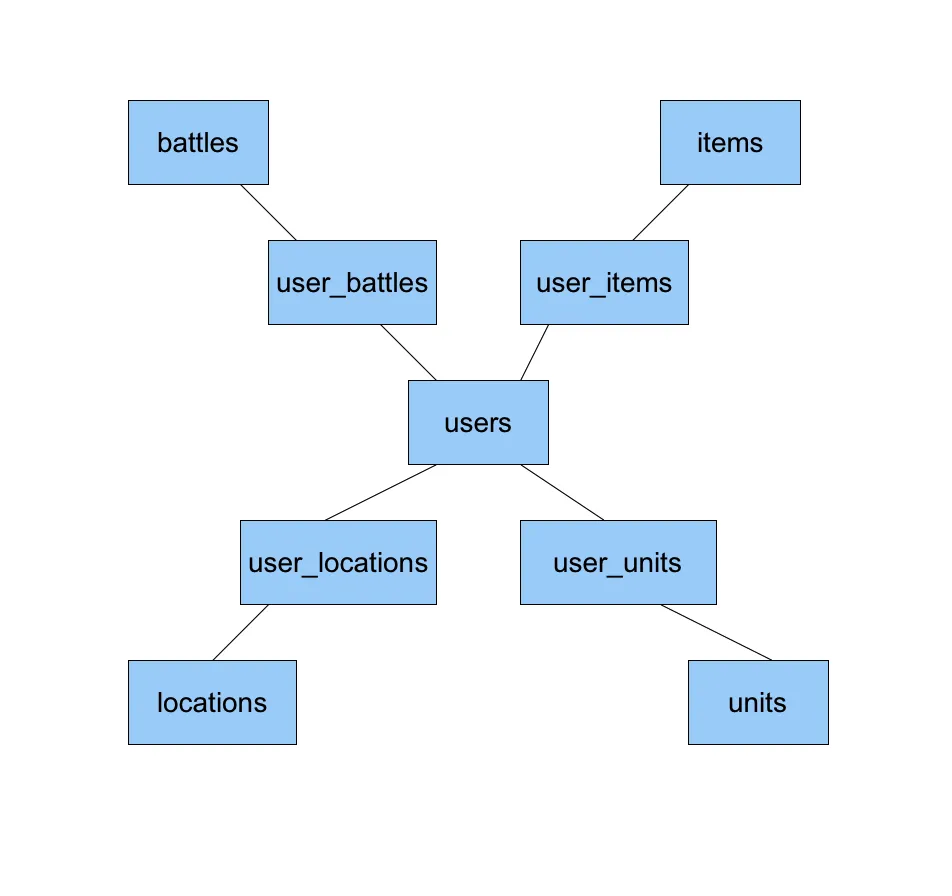 在转换为mongoDB时,我有几个选项:
在转换为mongoDB时,我有几个选项:
选项1(在用户中包含完整行):
选项1存在很多重复,因为我们添加了其他表的完整行。我看到的一个问题是,如果某个项目或战斗被更新,我们将不得不找到它在用户表中的所有出现并更新它们。但这给了我们一个优势,即始终拥有可在登录时交给客户端应用程序的完整用户对象。
选项2更具关系性,在用户表中只有其他表的mongoIds。这种选择的优点是更新战斗或物品没有太多成本,因为行只是引用而非复制。另一方面,当用户登录时,我们将不得不查找所有引用的单位、战斗、物品和位置,以响应完整的用户对象。
选项3与选项2相反,用户表的mongoIds保存在其他表中。我不太喜欢这个选项。
如果有人能指导我或提出更好的模型,我会非常感激。
基本上这是一个MMORPG游戏,多个客户端应用程序将通过Web服务连接到服务器。我们在客户端有一个本地数据库来存储数据。我希望有一个模型,使服务器能够响应完整的用户对象,然后更新或插入在客户端应用程序上更改的数据。
在转换为mongoDB时,我有几个选项:选项1(在用户中包含完整行):
users:{
_id:<user_id>,
battles:{[battle1, battle2, ...]},
items:{[item1, item2, ...]},
locations:{[location1, location2, ...]},
units:{[unit1, unit2, ...]},
}
battles:{
<battle_info>
}
locations:{
<location_info>
}
units:{
<units_info>
}
items:{
<items_info>
}
选项2(仅在用户中使用外键):
users:{
_id:<user_id>,
battles:{[battle1_id, battle2_id, ...]},
items:{[item1_id, item2_id, ...]},
locations:{[location1_id, location2_id, ...]},
units:{[unit1_id, unit2_id, ...]},
}
battles:{
<battle_info>
}
locations:{
<location_info>
}
units:{
<units_info>
}
items:{
<items_info>
}
选项3(在其他表中使用用户ID):
users:{
_id:<user_id>,
}
battles:{
<battle_info>,
user:{[user1_id, user2_id, ...]}
}
locations:{
<location_info>,
user:{[user1_id, user2_id, ...]}
}
units:{
<units_info>,
user:{[user1_id, user2_id, ...]}
}
items:{
<items_info>,
user:{[user1_id, user2_id, ...]}
}
选项1存在很多重复,因为我们添加了其他表的完整行。我看到的一个问题是,如果某个项目或战斗被更新,我们将不得不找到它在用户表中的所有出现并更新它们。但这给了我们一个优势,即始终拥有可在登录时交给客户端应用程序的完整用户对象。
选项2更具关系性,在用户表中只有其他表的mongoIds。这种选择的优点是更新战斗或物品没有太多成本,因为行只是引用而非复制。另一方面,当用户登录时,我们将不得不查找所有引用的单位、战斗、物品和位置,以响应完整的用户对象。
选项3与选项2相反,用户表的mongoIds保存在其他表中。我不太喜欢这个选项。
如果有人能指导我或提出更好的模型,我会非常感激。
基本上这是一个MMORPG游戏,多个客户端应用程序将通过Web服务连接到服务器。我们在客户端有一个本地数据库来存储数据。我希望有一个模型,使服务器能够响应完整的用户对象,然后更新或插入在客户端应用程序上更改的数据。