像大多数普通的PHP Web开发人员一样,我使用MySql作为关系型数据库管理系统。MySql(像其他关系型数据库管理系统一样)提供了SPATIAL INDEX功能,但我对其理解并不好。我已经在谷歌上搜索了相关内容,但没有找到清晰的实际示例来澄清我对它的错误认识。
有人能简要解释一下什么是SPATIAL INDEX以及何时应该使用吗?
像大多数普通的PHP Web开发人员一样,我使用MySql作为关系型数据库管理系统。MySql(像其他关系型数据库管理系统一样)提供了SPATIAL INDEX功能,但我对其理解并不好。我已经在谷歌上搜索了相关内容,但没有找到清晰的实际示例来澄清我对它的错误认识。
有人能简要解释一下什么是SPATIAL INDEX以及何时应该使用吗?
您可以使用空间索引对地理对象-形状进行索引。 空间索引使得能够高效搜索在空间上重叠的对象。
空间索引就像普通索引一样,不同之处在于空间对象不是1D数据点,而是在更高维度的空间中(例如2D),因此普通索引如BTree不适合用于索引此类数据。众所周知的空间索引技术是R树(在维基百科上搜索即可了解)。
空间索引允许您在多个列上高效地使用不等式进行查询
例如,使用空间索引,您可以高效地查询所有在矩形内的点,如下:
create table t(id integer primary key, x integer, y integer)
select * from mytable where x >= 1 and x < 10 and y >= 2 and y < 20
在x和y上都存在不等式。
更基本和常见的B树索引只能有效地加速一维不等式,即使你尝试使用在x和y上的复合索引。
例如,一个x-y复合B树索引将会:
x = 1 and y = 2:两列都有相等条件x = 1 and y > 2:第一列有相等条件,第二列有不等条件x > 1 and y > 2:两列都有不等条件,包括第一列x > 1 and y = 2:第一列有不等条件y > 2:这相当于x > -无穷大 and y > 2,所以这是复合B树索引的最坏情况。然而,这种情况可以通过B树索引高效解决。空间索引可以高效处理上述所有查询。
复合索引B树搜索为何会变慢的示例
这在以下链接中有很好的解释:https://dba.stackexchange.com/questions/249848/why-we-cant-have-more-than-one-inequality-condition-in-mysql-indexing/249909#249909
一种可视化B树的方式是看它如何对行进行排序。毕竟,它是类似于二叉搜索树的结构,只是每个节点有更多的条目以加快磁盘访问速度:
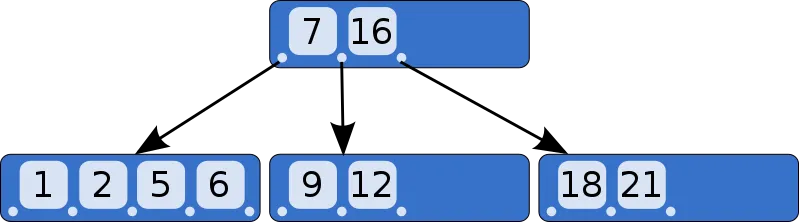
考虑以下的x-y复合索引,它按照(x, y)元组的字典顺序对所有行进行排序:
x|y
1|1
1|2
1|3
1|4
1|5
1|6
2|2
2|2
2|2
2|3
2|3
2|3
2|4
2|4
2|4
4|2
4|2
4|2
4|3
4|3
4|3
4|4
4|4
4|4
5|3
5|4
5|5
5|6
5|7
5|8
x > 0 and y > 4
我们能做的唯一加速操作是在上述索引上进行二分查找。
首先,它使用索引对(1, 5)进行二叉树搜索,这比完全扫描要快。
然后,按索引顺序获取每个较大的y,以x = 1为例。到目前为止还不错。
问题是接下来会发生什么。
请注意,在这种情况下,对于x = 2和x = 4,没有y > 4。
然而,无法立即从索引中知道这一点并直接跳转到x = 5!
搜索所需要做的就是:我已经完成了x = 1,现在给我下一个更大的x。因此,它线性地遍历索引树,直到找到下一个值。
然后它找到第一个(2, 2),它知道:好了,存在x = 2。现在它有两个选择:
哪个更好取决于数据库中总共有多少行,因为新的二分搜索是log(n),所以除非存在大量的x = 2且y < 5的值,否则不值得。
使用其中任一种方法都会判断x = 2没有结果,因此我们只是浪费了一些时间扫描许多无效的行。
所以它继续上述过程,基本上扫描整个索引。
x = 4像x = 2一样被无用地扫描并没有结果。
然后继续遍历索引并找到x = 5,最终达到(5, 5),我们终于有了一些结果。
因此,正如我们所看到的,这需要跨越可能不包含任何感兴趣结果的范围,这就是为什么这个复合B树索引在搜索大范围的x和许多空的y命中时只能产生有限的加速。
空间索引的R树实现看起来更像这样:
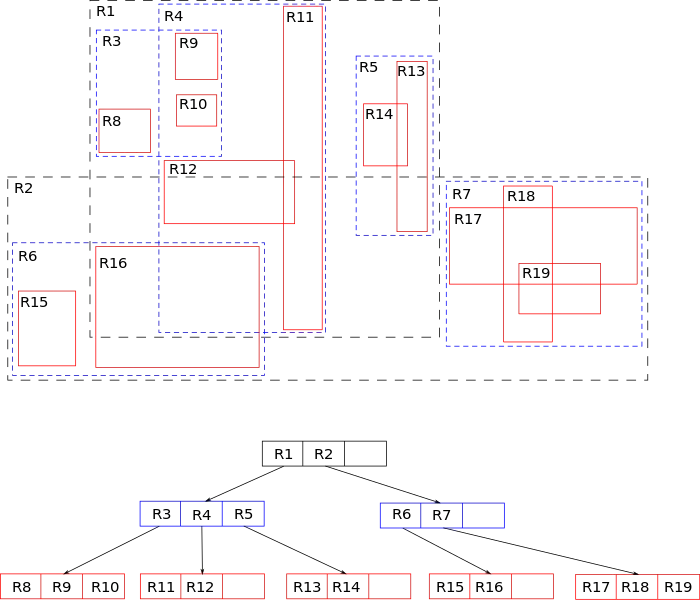
所以我们直观地理解,它实际上试图将一个二维空间分割成一堆平衡的矩形,因此能够高效地查询任意矩形区域。
SQLite最小基准测试
我对MySQL不是很熟悉,但概念应该是类似的。
我将创建两个测试数据库,每个数据库中有1000万个点,这些点在一条倾斜度为2的直线上:
然后让我们提出问题:
x >= 1000000且x < 2000000且y >= 4000000且y < 6000000之间有多少个点?
使用以下查询:
time sqlite3 100mr.sqlite 'select count(*) from t where x >= 10000000 and x < 90000000 and y >= 50000000 and y < 60000000'
from pathlib import Path
import csv
import sqlite3
f = '100mr.sqlite'
n = 100000000
Path(f).unlink(missing_ok=True)
connection = sqlite3.connect(f)
cursor = connection.cursor()
cursor.execute('CREATE VIRTUAL TABLE t using rtree(id, x, x2, y, y2)')
cursor.executemany('INSERT INTO t VALUES (?, ?, ?, ?, ?)', ((None, str(i), str(i), str(i*2), str(i*2)) for i in range (n)))
connection.commit()
connection.close()
rm -f "$f"
time sqlite3 "$f" 'create table t(id integer, x integer, y integer)'
time sqlite3 "$f" 'insert into t select value as id, value as x, value * 2 as y from generate_series(0,99999999)'
time sqlite3 "$f" 'create index txy on t(x, y)'
使用空间索引最适合搜索精确匹配值查找,而不是范围扫描。它主要支持MyISAM表,但从MySQL 5.7.4 LAB版本开始,Innodb也支持它。
References:- http://dev.mysql.com/doc/refman/5.5/en/creating-spatial-indexes.html http://mysqlserverteam.com/innodb-spatial-indexes-in-5-7-4-lab-release/
{kind=link}
{kind=link}