我在查看维基百科的KD树页面。作为一个例子,我用Python实现了列出的构建KD树的算法。
然而,使用KD树进行KNN搜索的算法切换到另一种语言并不是完全清晰的。英文解释开始让人感到有道理,但其中的某些部分(例如他们“展开递归”以检查其他叶节点的区域)对我来说并没有任何意义。
这是如何工作的,如何在Python中使用KD树进行KNN搜索?这不是要求“给我代码!”类型的问题,我也不指望得到这样的回答。请简要说明一下:)
我在查看维基百科的KD树页面。作为一个例子,我用Python实现了列出的构建KD树的算法。
然而,使用KD树进行KNN搜索的算法切换到另一种语言并不是完全清晰的。英文解释开始让人感到有道理,但其中的某些部分(例如他们“展开递归”以检查其他叶节点的区域)对我来说并没有任何意义。
这是如何工作的,如何在Python中使用KD树进行KNN搜索?这不是要求“给我代码!”类型的问题,我也不指望得到这样的回答。请简要说明一下:)
这本书的介绍,第3页:
给定d维空间中的一组n个点,kd树的构建过程如下。首先,找到点的第i个坐标值的中位数(最开始时,i=1)。也就是说,计算出一个值M,使得至少50%的点的第i个坐标值大于或等于M,而至少50%的点的第i个坐标值小于或等于M。将x的值存储下来,并将集合P分成PL和PR,其中PL仅包含其第i个坐标值小于或等于M的点,而|PR|=|PL|±1。然后在PL和PR上递归地重复此过程,并用i + 1(如果i = d,则为1)替换i。当节点中的点的数量为1时,递归停止。
以下段落讨论了它在解决最近邻问题中的使用。
或者,这是Jon Bentley的1975年原始论文。
编辑:我应该补充说明Scipy有一个kdtree实现:
closest_point的第一阶段是一个简单的深度优先搜索,以找到最佳匹配的叶节点。
与其仅仅将找到的最佳节点返回给调用堆栈,第二阶段检查是否可能在“远离”侧存在更近的节点:(ASCII艺术图)
n current node
b | best match so far
| p | point we're looking for
|< >| | error
|< >| distance to "away" side
|< | >| error "sphere" extends to "away" side
| x possible better match on the "away" side
n沿着一条线将空间分割,因此我们只需要在“远离”一侧查看,如果点p和最佳匹配b之间的“误差”大于从点p到线段的距离,则需要查看“远离”一侧是否有更接近的点。
由于我们最佳匹配的节点被传递到这个第二个测试中,它不必对分支进行完整遍历,如果它走错了路(只向下遍历“近”子节点,直到达到叶子节点),它会很快停止。
为了计算点p和通过节点n分割空间的线之间的距离,我们可以通过将适当的坐标复制为轴来简单地将点“投影”到轴上,因为所有轴都是正交的(水平或垂直)。
让我们考虑一个例子,为了简单起见,假设d=2,Kd树的结果如下所示
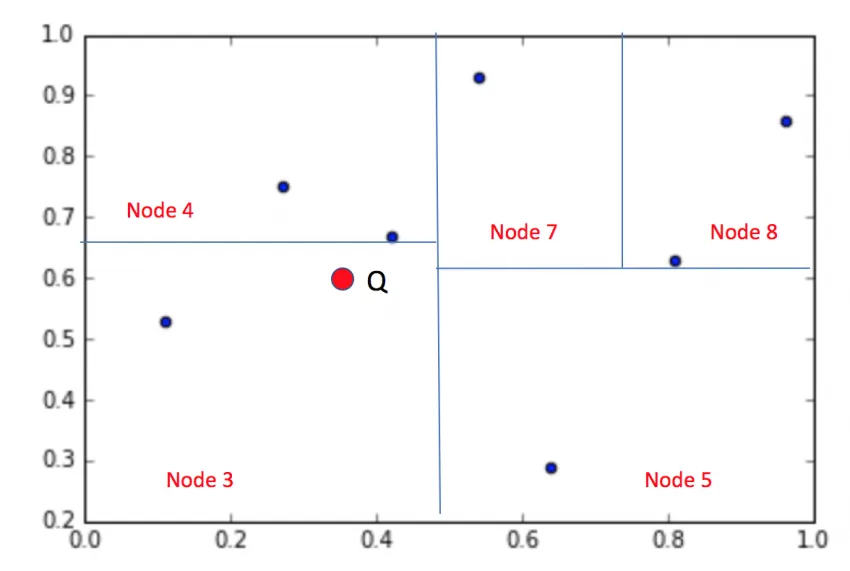
您的查询点是Q,您想找到k个最近邻居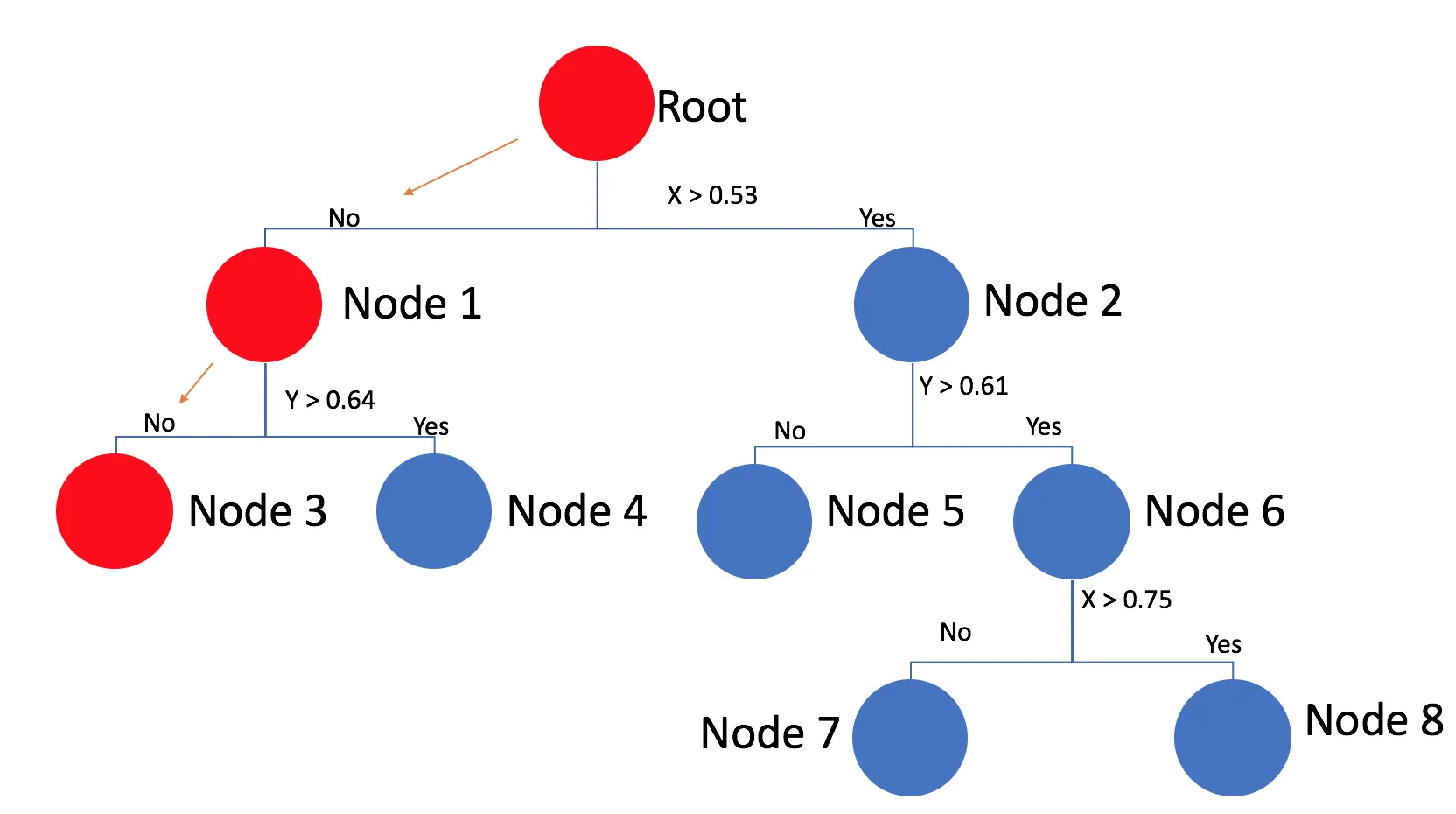
上述树是kd-tree的表示方式
我们将通过树进行搜索以落入其中一个区域。在kd-tree中,每个区域由单个点表示。
然后,我们将找出该点与查询点之间的距离
然后,我们将绘制一个半径为该距离的圆来确保是否有任何点更接近查询点。
然后,我们回溯到那些在该圆形区域内的轴,并找到附近的点。