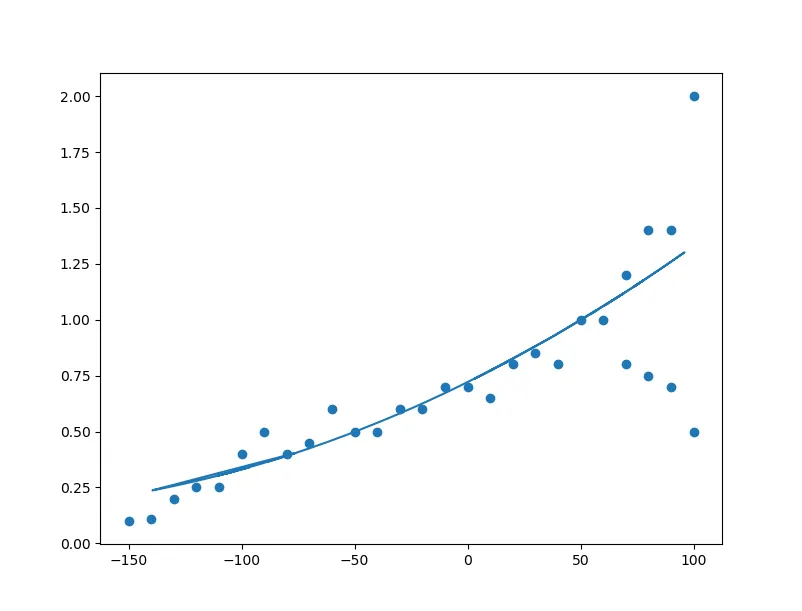
我目前正在尝试对许多河流的行为进行分类。其中许多河流的行为非常类似于二次多项式。
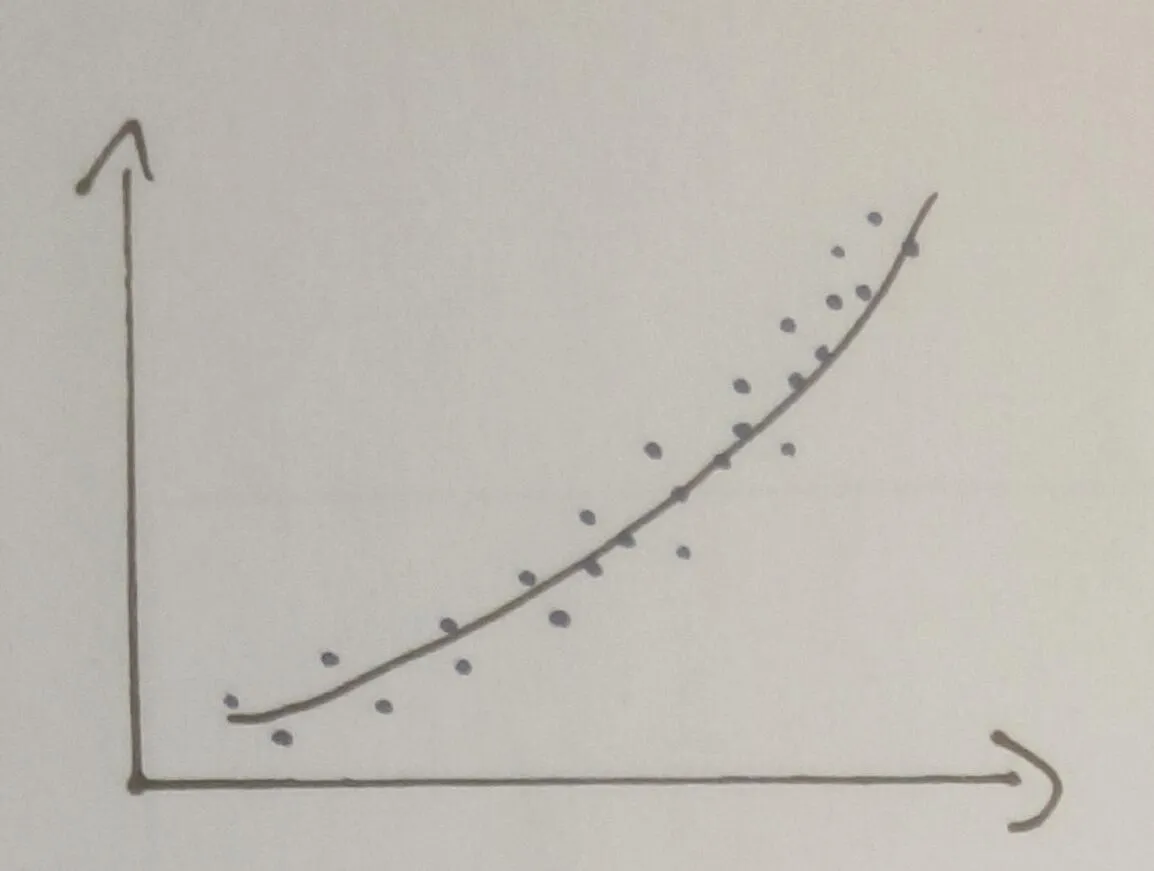
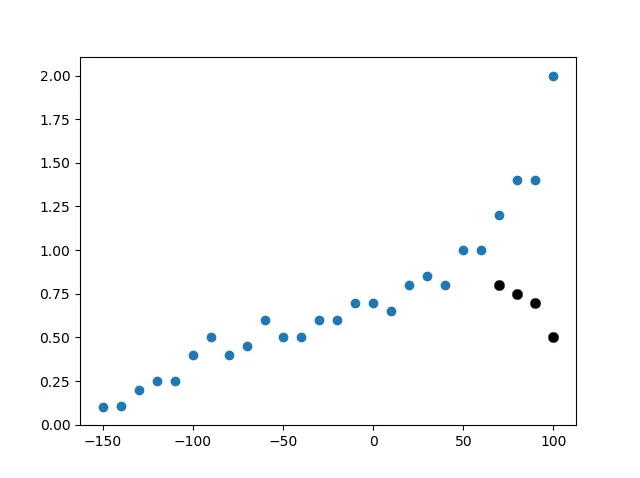
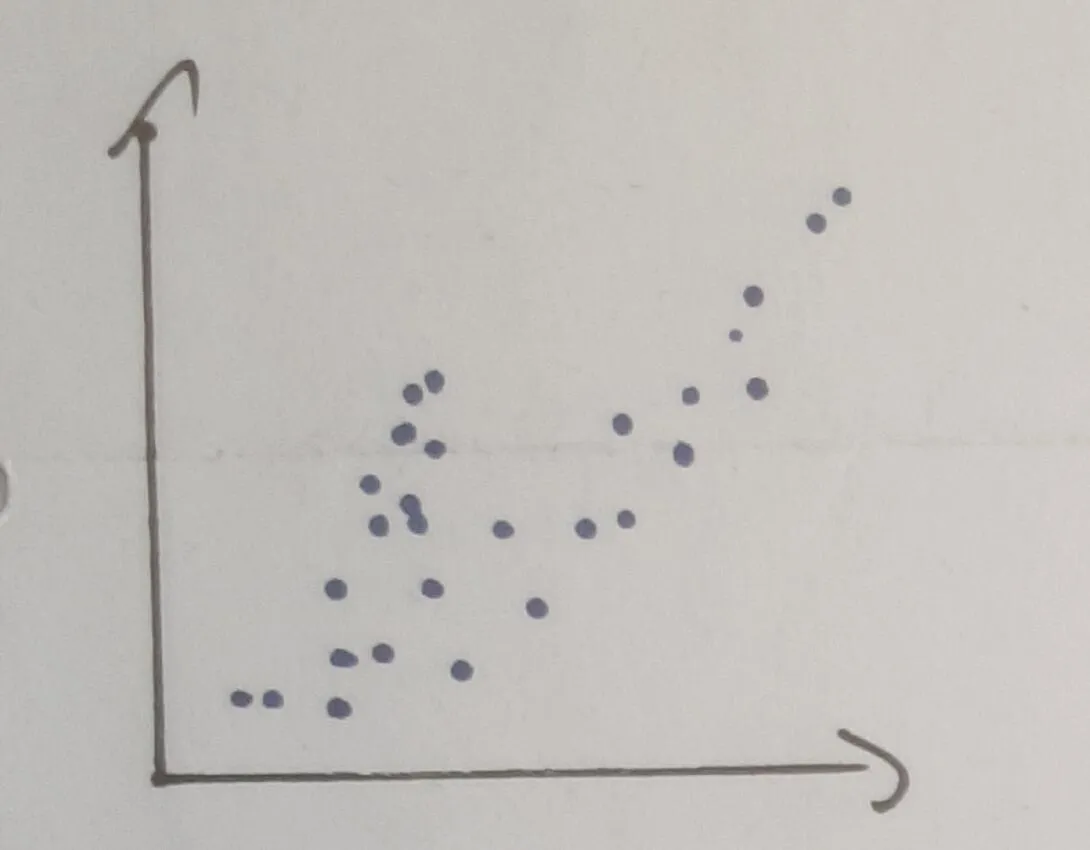 我想通过计算所有点距离简单多项式的距离来对其进行分类。因此,它基本上看起来像这样:
我想通过计算所有点距离简单多项式的距离来对其进行分类。因此,它基本上看起来像这样:
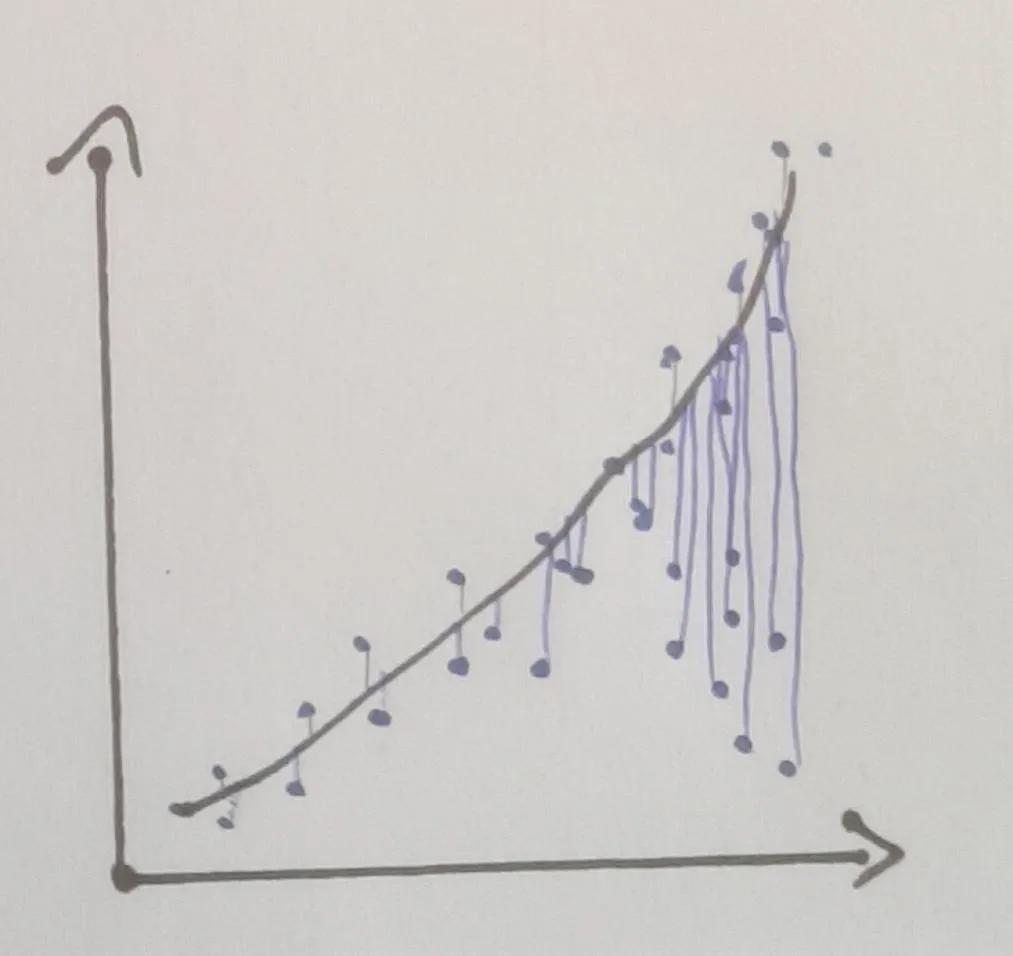
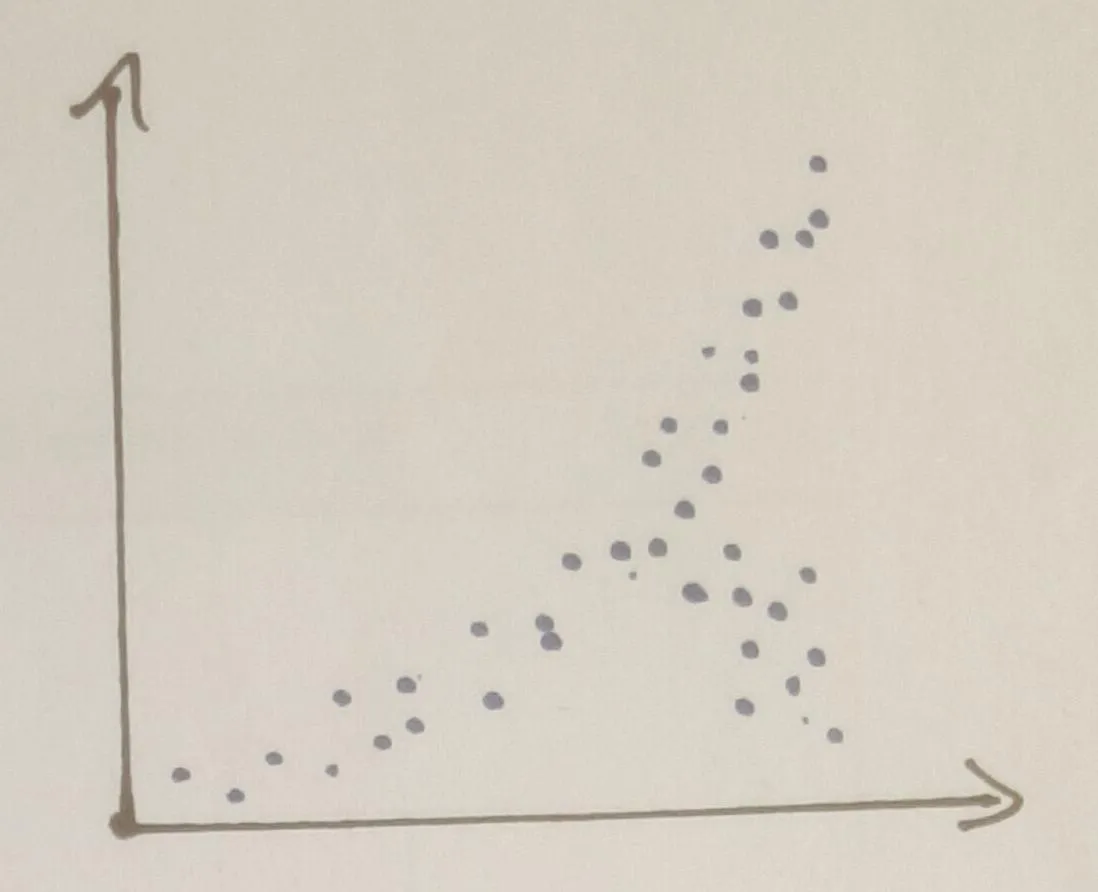
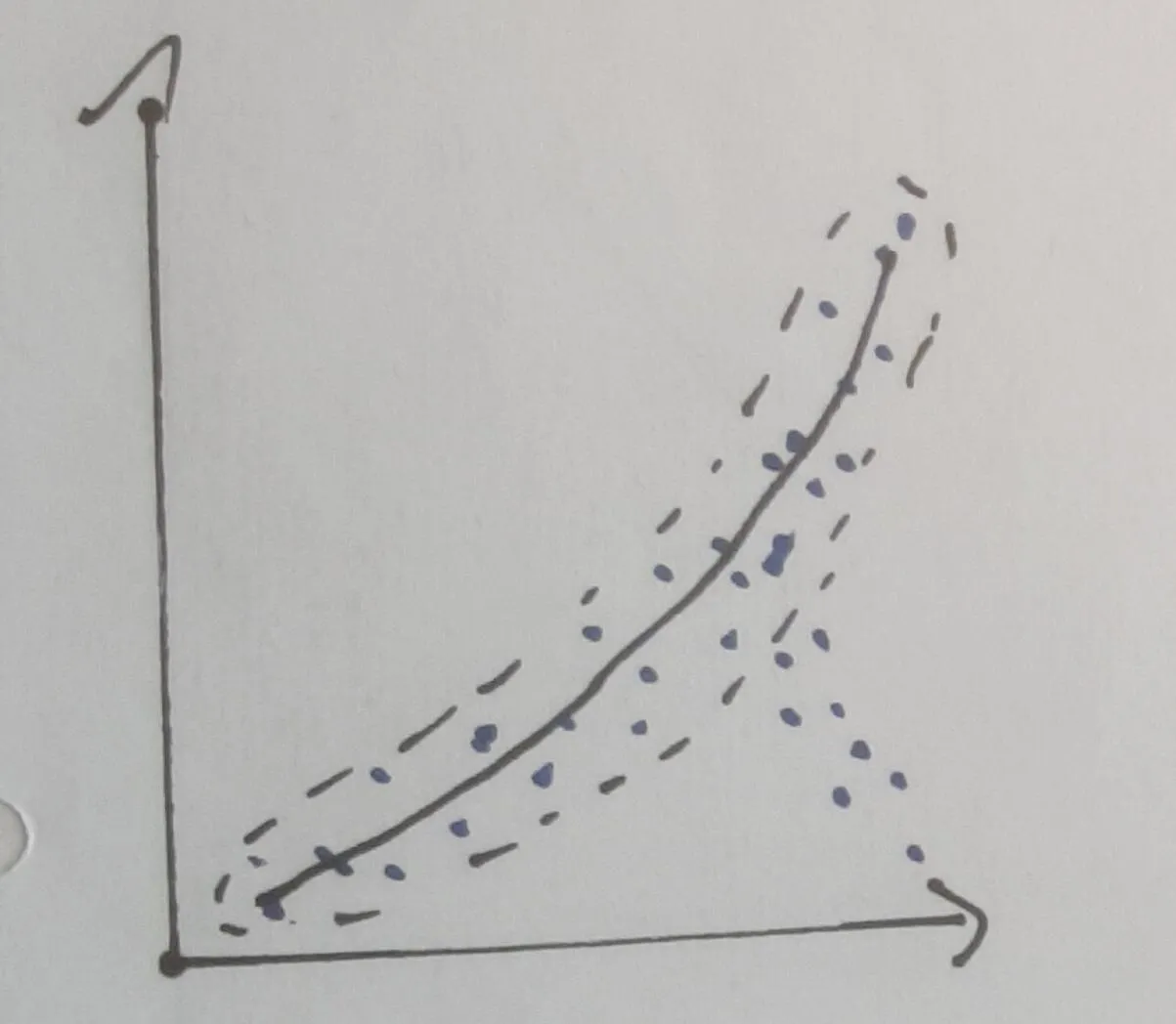
但是为了能够做到这一点,我必须仅为那些“正常行为”的点计算多项式。否则,我的多项式会偏向于发散行为的方向,我将无法正确计算距离。
x_test = [-150,-140,-130,-120,-110,-100,-90,-80,-70,-60,-50,-40,-30,-20,-10,0,10,20,30,40,50,60,70,70,80,80,90,90,100,100]
y_test = [0.1,0.11,0.2,0.25,0.25,0.4,0.5,0.4,0.45,0.6,0.5,0.5,0.6,0.6,0.7, 0.7,0.65,0.8,0.85,0.8,1,1,1.2,0.8,1.4,0.75,1.4,0.7,2,0.5]
我可以使用numpy从中创建一个多项式。
fit = np.polyfit(x_test, y_test, deg=2, full=True)
polynom = np.poly1d(fit[0])
simulated_data = polynom(x)
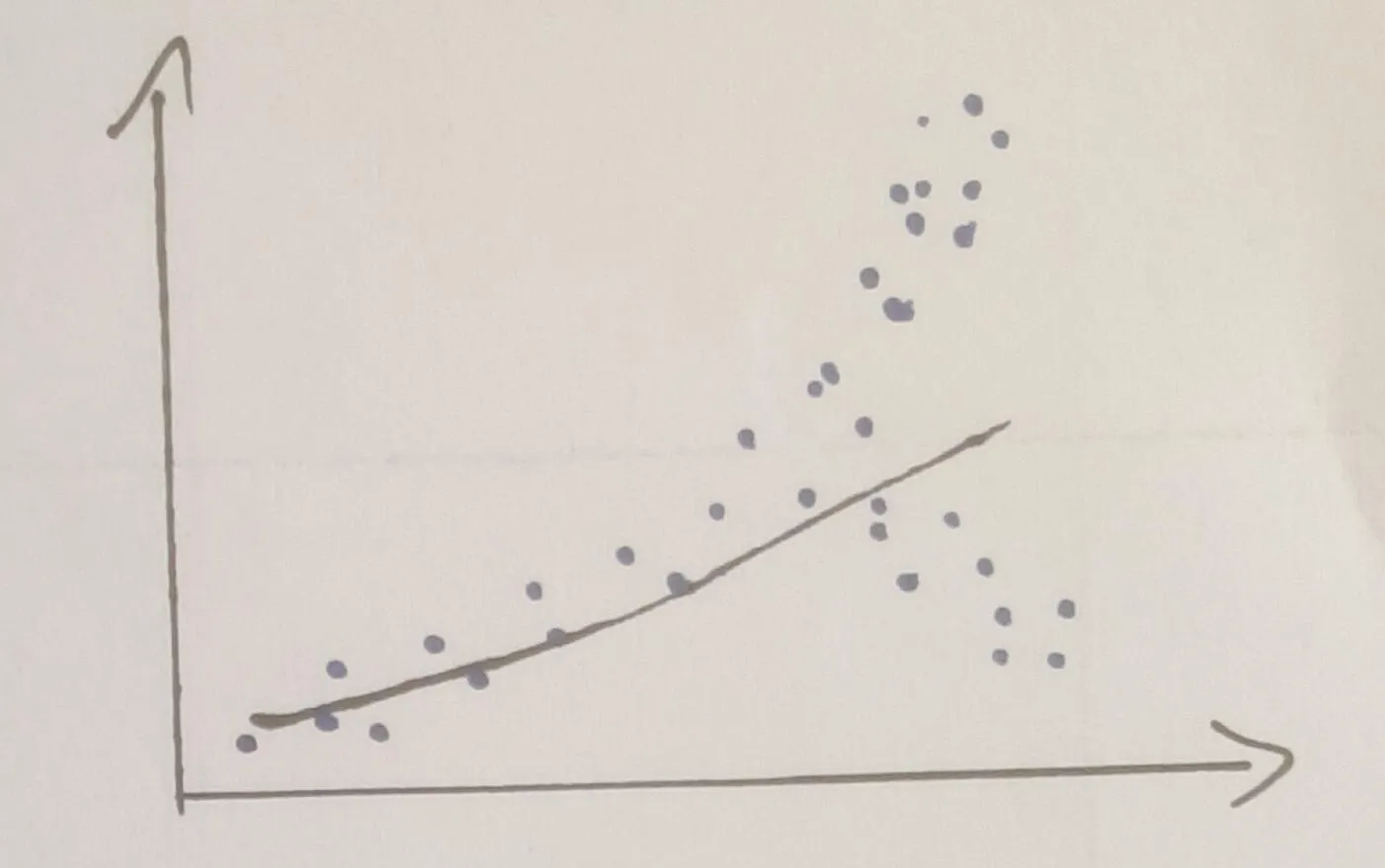
当我绘制它时,我得到以下结果:
ax = plt.gca()
ax.scatter(x_test,y_test)
ax.plot(x, simulated_data)