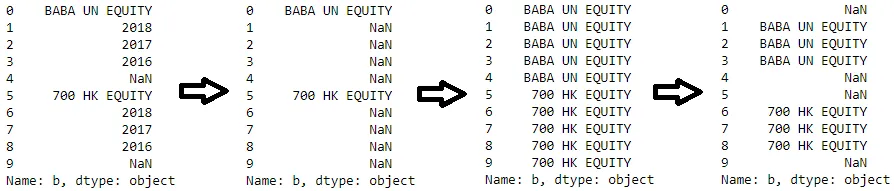
假设我有以下 Pandas DataFrame:
a b
0 NAN BABA UN EQUITY
1 NAN 2018
2 NAN 2017
3 NAN 2016
4 NAN NAN
5 NAN 700 HK EQUITY
6 NAN 2018
7 NAN 2017
8 NAN 2016
9 NAN NAN
对于列 b 中的每个单元格,我想要检查它是否包含字符串 EQUITY。如果是,我想要用上一行中的前一个字符串替换列 a 中的单元格,直到出现一个值为 NAN 的行,并得到编辑后的 DataFrame 如下:
a b
0 NAN BABA UN EQUITY
1 BABA UN EQUITY 2018
2 BABA UN EQUITY 2017
3 BABA UN EQUITY 2016
4 NAN NAN
5 NAN 700 HK EQUITY
6 700 HK EQUITY 2018
7 700 HK EQUITY 2017
8 700 HK EQUITY 2016
9 NAN NAN
我的实际DataFrame比上面的要大得多,但格式类似。我遇到了一个问题,无法弄清楚如何检查单元格是否包含EQUITY。看起来应该使用str.contains,但我不清楚如何做到这一点。
na=True参数来替代!= False在str.contains中吗?(或根据需要使用na=False。) - jpppattern='wiring | media | elect | tape'v=pd.Series(['electricity fault'])s=v.str.contains(pattern, flags=re.IGNORECASE, regex=True)print(s)[Out]0 Falsedtype: bool为什么呢? 如果您能帮助我,我将不胜感激。 - pink.slashpattern='wiring |media|elect|tape'v=pd.Series(['electricity fault']) s=v.str.contains(pattern, flags=re.IGNORECASE, regex=True)输出0 True- pink.slash