我正在尝试对数据集样本使用高斯混合模型。
我既使用了MLlib(与pyspark一起),也使用了scikit-learn,结果非常不同,scikit-learn的结果看起来更加真实。
from pyspark.mllib.clustering import GaussianMixture as SparkGaussianMixture
from sklearn.mixture import GaussianMixture
from pyspark.mllib.linalg import Vectors
Scikit-learn:
local = pd.DataFrame([ x.asDict() for x in df.sample(0.0001).collect() ])
model1 = GaussianMixture(n_components=3)
model1.fit([ [x] for x in local['field'].tolist() ])
model1.means_
array([[7.56123598e+00],
[1.32517410e+07],
[3.96762639e+04]])
model1.covariances_
array([[[6.65177423e+00]],
[[1.00000000e-06]],
[[8.38380897e+10]]])
MLLib:
model2 = SparkGaussianMixture.train(
sc.createDataFrame(local).rdd.map(lambda x: Vectors.dense(x.field)),
k=3,
convergenceTol=1e-4,
maxIterations=100
)
model2.gaussians
[MultivariateGaussian(mu=DenseVector([28736.5113]), sigma=DenseMatrix(1, 1, [1094083795.0001], 0)),
MultivariateGaussian(mu=DenseVector([7839059.9208]), sigma=DenseMatrix(1, 1, [38775218707109.83], 0)),
MultivariateGaussian(mu=DenseVector([43.8723]), sigma=DenseMatrix(1, 1, [608204.4711], 0))]
然而,我有兴趣将整个数据集通过模型运行,但我担心这将需要并行化(因此使用MLlib),以在有限的时间内获得结果。 我是否做错了什么/遗漏了什么?
数据:
完整的数据具有极长的尾部,并且如下所示:
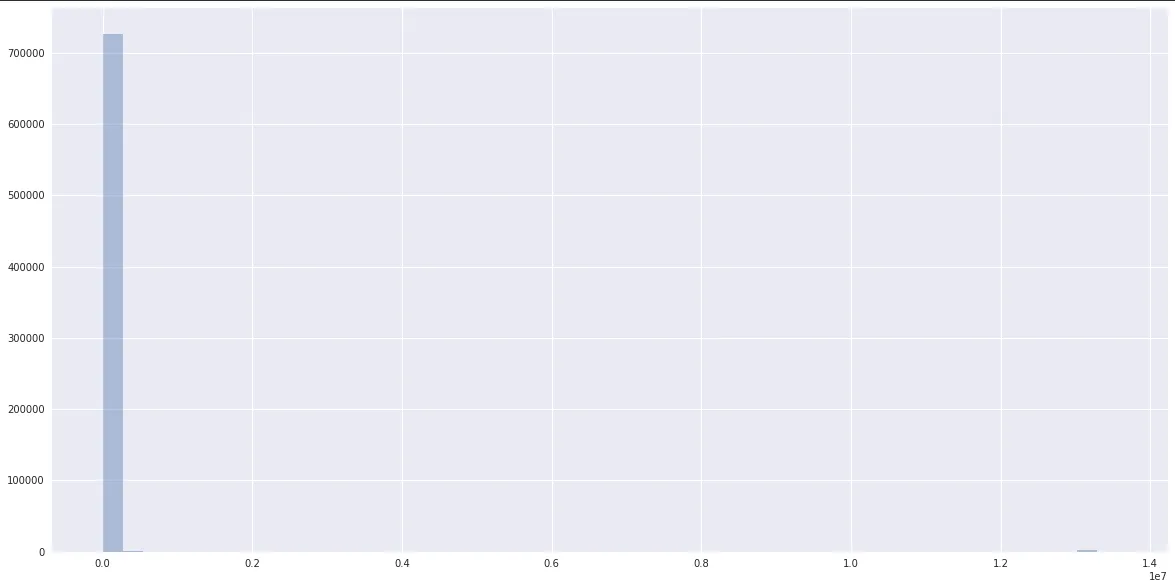
而数据则明显呈现出接近于一个聚集在scikit-learn附近的正态分布:
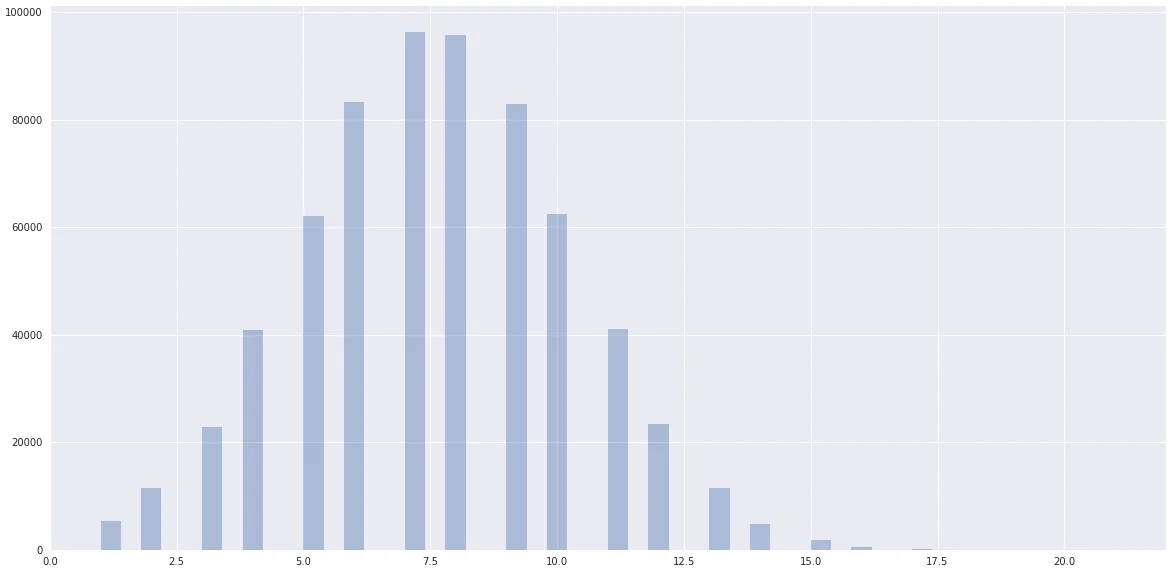
我正在使用Spark 2.3.0 (AWS EMR)。
编辑:初始化参数:
local = pd.DataFrame([ x.asDict() for x in df.sample(0.0001).collect() ])
model1 = GaussianMixture(n_components=3, init_params='random')
model1.fit([ [x] for x in local['field'].tolist() ])
model1.means_
array([[2.17611913e+04],
[8.03184505e+06],
[7.56871801e+00]])
model1.covariances_
rray([[[1.01835902e+09]],
[[3.98552130e+13]],
[[6.95161493e+00]]])
scikit-learn的帖子。没有改变任何东西。 - ixaxaar