现在我遇到了一个很大的障碍。
我正在使用PostgreSQL 10及其新的表分区功能。
有时许多查询不返回结果,同时当我通过pg_stat_activity检查后端进程时,许多后端进程是活动的。一开始,我认为这些进程只是在等待锁定,但是这些事务仅包含SELECT语句,其他后端没有使用需要ACCESS EXCLUSIVE锁的任何查询。而且这些仅包含SELECT语句的查询在计划方面也没有问题,并且通常工作正常。计算机资源(CPU、内存、IO、网络)也没有问题。因此,这些事务应该永远不会发生冲突。并且我通过pg_locks和pg_blocking_pids()彻底检查了这些事务的锁定,最终我未能找到任何使查询变慢的锁定。许多处于活动状态的后端仅持有ACCESS SHARE锁,因为它们仅使用SELECT。
现在我认为这些现象不是由锁引起的,而与新的表分区相关。
那么,为什么会有许多后端处于活动状态呢?
能否有人帮助我?任何评论都将不胜感激。
下面的图片是pg_stat_activity结果的一部分。如果您需要其他信息,请告诉我。
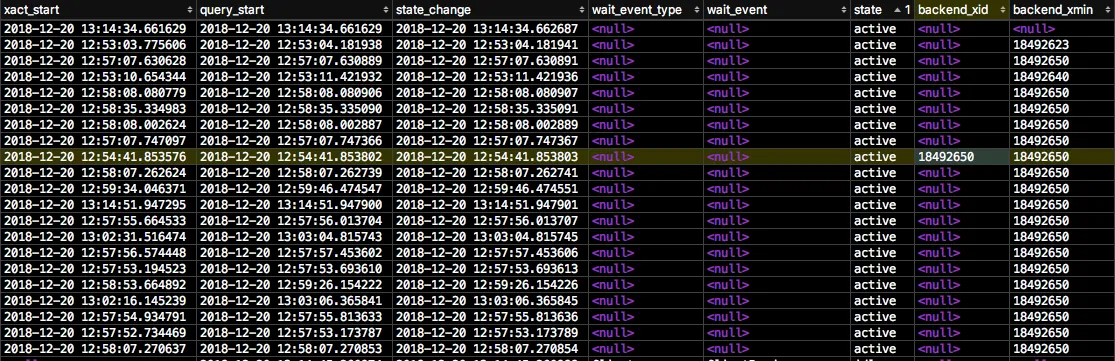
编辑
我的查询不处理大量数据。返回类型如下:
uuid UUID
,number BIGINT
,title TEXT
,type1 TEXT
,data_json JSONB
,type2 TEXT
,uuid_array UUID[]
,count BIGINT
由于它有JSONB列,我无法计算出确切的值,但它不是大型JSON。
通常这些查询速度适中(约1.5秒),因此绝对没有问题,但当其他进程工作时,会发生这种现象。
如果统计信息不正确,则查询始终很慢。
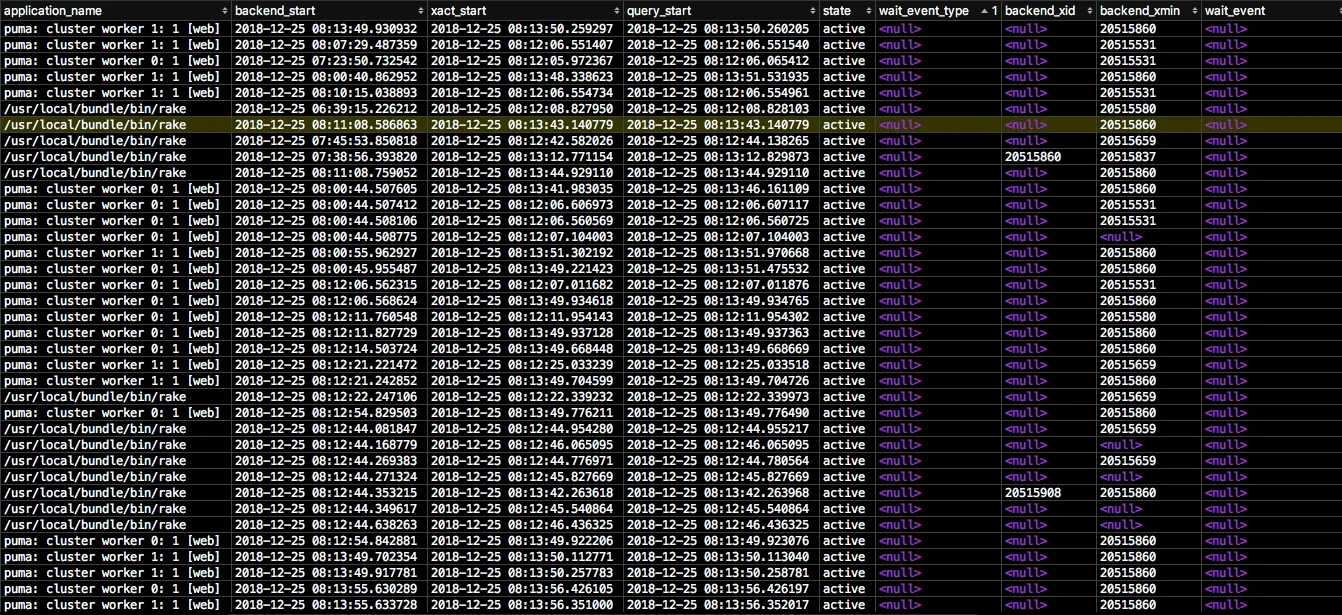
编辑2
这是统计数据。由于连接数接近100,我无法显示所有统计信息。
- 当您的查询从表中返回大量数据并且您将该数据显示在查询工具上而不是插入到其他表或进行任何其他操作时,有时会出现这种情况。 您不应仅为了显示大量数据而进行查询。
- 或者可能是由于缺少统计信息。请对该表进行分析和清理。您能否发布查询和返回的数据量?
- Anuraag Veerapaneniwork_mem和shared_buffers,这确实有所帮助。在你的情况下,我会采取同样的方式。我们通过DataDog监控我们的DB服务器,如果你有类似的监控可用,你可能可以调整配置来解决你的问题。我们使用的是9.3版本,没有分区表。 - Sergey Telshevskywork_mem从4MB改为32MB。然而,出现了一些问题。我没有改变shared_buffers,因为shared_buffers大于内存的30%。在您的情况下,您如何处理这些参数? - Kazuya Tomita