我们的一个较小的数据库机器上一直在运行着一个非常长时间的自动清理进程,我们认为这个进程一直在使用大量的。通过运行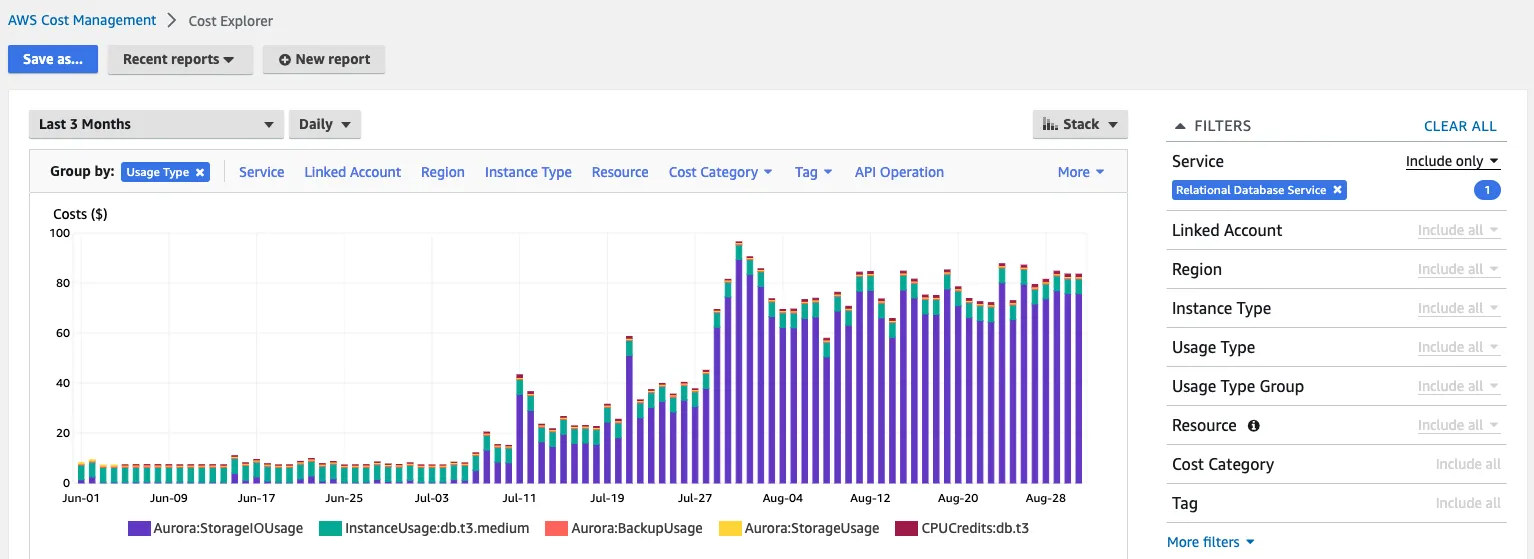
我对Postgres不太熟悉,想知道是什么原因导致需要清理这么多记录,而且考虑到我们一直将
我们
SELECT * FROM pg_stat_activity WHERE wait_event_type = 'IO';并反复看到以下结果,我们得出了这个结论。
datid | datname | pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | xact_start | query_start | state_change | wait_event_type | wait_event | state | backend_xid | backend_xmin | query | backend_type
--------+----------------------------+-------+----------+-----------+------------------+----------------+-----------------+-------------+-------------------------------+-------------------------------+-------------------------------+-------------------------------+-----------------+--------------+--------+-------------+--------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------------
398954 | postgres | 17582 | | | | | | | 2022-09-29 18:45:55.364654+00 | 2022-09-29 18:46:20.253107+00 | 2022-09-29 18:46:20.253107+00 | 2022-09-29 18:46:20.253108+00 | IO | DataFileRead | active | | 66020718 | autovacuum: VACUUM pg_catalog.pg_depend | autovacuum worker
398954 | postgres | 17846 | | | | | | | 2022-09-29 18:46:04.092536+00 | 2022-09-29 18:46:29.196309+00 | 2022-09-29 18:46:29.196309+00 | 2022-09-29 18:46:29.19631+00 | IO | DataFileRead | active | | 66020732 | autovacuum: VACUUM pg_toast.pg_toast_2618 | autovacuum worker
从截图中可以看到,已经运行了一个多月,主要是针对pg_depend、pg_attribute和pg_toast_2618表进行的,这些表并不是很大。除了可能是从生产环境恢复数据库(这是我们较低级别的环境之一)之外,我没有找到任何理由说明为什么需要这么多的清理。以下是这些表以及pg_toast_2618关联的pg_rewrite的pg_stat_sys_tables条目:
relid | schemaname | relname | seq_scan | seq_tup_read | idx_scan | idx_tup_fetch | n_tup_ins | n_tup_upd | n_tup_del | n_tup_hot_upd | n_live_tup | n_dead_tup | n_mod_since_analyze | last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | vacuum_count | autovacuum_count | analyze_count | autoanalyze_count
-------+------------+---------------+----------+--------------+----------+---------------+-----------+-----------+-----------+---------------+------------+------------+---------------------+-------------+-------------------------------+--------------+-------------------------------+--------------+------------------+---------------+-------------------
1249 | pg_catalog | pg_attribute | 185251 | 12594432 | 31892996 | 119366792 | 1102817 | 3792 | 1065737 | 1281 | 543392 | 1069529 | 23584 | | 2022-09-29 18:53:25.227334+00 | | 2022-09-28 01:12:47.628499+00 | 0 | 1266763 | 0 | 36
2608 | pg_catalog | pg_depend | 2429 | 369003445 | 14152628 | 23494712 | 7226948 | 0 | 7176855 | 0 | 476267 | 7176855 | 0 | | 2022-09-29 18:52:34.523257+00 | | 2022-09-28 02:02:52.232822+00 | 0 | 950137 | 0 | 71
2618 | pg_catalog | pg_rewrite | 25 | 155083 | 1785288 | 1569100 | 64127 | 314543 | 62472 | 59970 | 7086 | 377015 | 13869 | | 2022-09-29 18:53:11.288732+00 | | 2022-09-23 18:54:50.771969+00 | 0 | 1280018 | 0 | 81
2838 | pg_toast | pg_toast_2618 | 0 | 0 | 1413436 | 3954640 | 828571 | 0 | 825143 | 0 | 15528 | 825143 | 1653714 | | 2022-09-29 18:52:47.242386+00 | | | 0 | 608881 | 0 | 0
我对Postgres不太熟悉,想知道是什么原因导致需要清理这么多记录,而且考虑到我们一直将
autovacuum设置为TRUE,为什么需要超过一个月的时间才能完成。我们正在单个db.t3.medium上运行Postgres版本10.17,目前唯一想到的就是尝试增加实例大小。难道我们只需要增加Aurora群集上的数据库实例大小,以便更多地使用内存执行此操作吗?我对如何减少这种持续巨大的存储IO成本感到有些困惑。我们
autovaccum设置的其他信息:=> SELECT * FROM pg_catalog.pg_settings WHERE name LIKE '%autovacuum%';
name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals | boot_val | reset_val | sourcefile | sourceline | pending_restart
-------------------------------------+-----------+------+-------------------------------------+-------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------+------------+---------+--------------------+---------+------------+-----------------------------------------------------------------------------------------+-----------+-----------+-----------------------------------+------------+-----------------
autovacuum | on | | Autovacuum | Starts the autovacuum subprocess. | | sighup | bool | configuration file | | | | on | on | /rdsdbdata/config/postgresql.conf | 78 | f
autovacuum_analyze_scale_factor | 0.05 | | Autovacuum | Number of tuple inserts, updates, or deletes prior to analyze as a fraction of reltuples. | | sighup | real | configuration file | 0 | 100 | | 0.1 | 0.05 | /rdsdbdata/config/postgresql.conf | 55 | f
autovacuum_analyze_threshold | 50 | | Autovacuum | Minimum number of tuple inserts, updates, or deletes prior to analyze. | | sighup | integer | default | 0 | 2147483647 | | 50 | 50 | | | f
autovacuum_freeze_max_age | 200000000 | | Autovacuum | Age at which to autovacuum a table to prevent transaction ID wraparound. | | postmaster | integer | default | 100000 | 2000000000 | | 200000000 | 200000000 | | | f
autovacuum_max_workers | 3 | | Autovacuum | Sets the maximum number of simultaneously running autovacuum worker processes. | | postmaster | integer | configuration file | 1 | 262143 | | 3 | 3 | /rdsdbdata/config/postgresql.conf | 45 | f
autovacuum_multixact_freeze_max_age | 400000000 | | Autovacuum | Multixact age at which to autovacuum a table to prevent multixact wraparound. | | postmaster | integer | default | 10000 | 2000000000 | | 400000000 | 400000000 | | | f
autovacuum_naptime | 5 | s | Autovacuum | Time to sleep between autovacuum runs. | | sighup | integer | configuration file | 1 | 2147483 | | 60 | 5 | /rdsdbdata/config/postgresql.conf | 9 | f
autovacuum_vacuum_cost_delay | 5 | ms | Autovacuum | Vacuum cost delay in milliseconds, for autovacuum. | | sighup | integer | configuration file | -1 | 100 | | 20 | 5 | /rdsdbdata/config/postgresql.conf | 73 | f
autovacuum_vacuum_cost_limit | -1 | | Autovacuum | Vacuum cost amount available before napping, for autovacuum. | | sighup | integer | default | -1 | 10000 | | -1 | -1 | | | f
autovacuum_vacuum_scale_factor | 0.1 | | Autovacuum | Number of tuple updates or deletes prior to vacuum as a fraction of reltuples. | | sighup | real | configuration file | 0 | 100 | | 0.2 | 0.1 | /rdsdbdata/config/postgresql.conf | 22 | f
autovacuum_vacuum_threshold | 50 | | Autovacuum | Minimum number of tuple updates or deletes prior to vacuum. | | sighup | integer | default | 0 | 2147483647 | | 50 | 50 | | | f
autovacuum_work_mem | -1 | kB | Resource Usage / Memory | Sets the maximum memory to be used by each autovacuum worker process. | | sighup | integer | default | -1 | 2147483647 | | -1 | -1 | | | f
log_autovacuum_min_duration | -1 | ms | Reporting and Logging / What to Log | Sets the minimum execution time above which autovacuum actions will be logged. | Zero prints all actions. -1 turns autovacuum logging off. | sighup | integer | default | -1 | 2147483647 | | -1 | -1 | | | f
rds.force_autovacuum_logging_level | disabled | | Customized Options | Emit autovacuum log messages irrespective of other logging configuration. | Each level includes all the levels that follow it.Set to disabled to disable this feature and fall back to using log_min_messages. | sighup | enum | default | | | {debug5,debug4,debug3,debug2,debug1,info,notice,warning,error,log,fatal,panic,disabled} | disabled | disabled | | | f
db.t3.large,问题立即消失了。有什么想法为什么这样做可以解决快照仍然能够看到元组的问题,但重新启动实例却不能解决? - Brian