我希望将下面两个数据框的行合并,当DF2中Test1列的字符串包含DF1中Test1列的子字符串时。
DF1 = pd.DataFrame({'Test1':list('ABC'),
'Test2':[1,2,3]})
print (DF1)
Test1 Test2
0 A 1
1 B 2
2 C 3
DF2 = pd.DataFrame({'Test1':['ee','bA','cCc','D'],
'Test2':[1,2,3,4]})
print (DF2)
Test1 Test2
0 ee 1
1 bA 2
2 cCc 3
3 D 4
为此,我可以使用“str contains”来识别DF2.Test1字符串中包含的DF1.Test1子字符串。
输入:
for i in DF1.Test1:
ok = DF2[Df2.Test1.str.contains(i)]
print(ok)
输出:
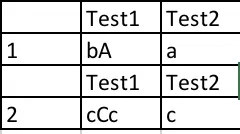
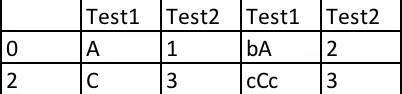
现在,我想在输出中添加Test1子字符串与Test2字符串匹配的合并结果
输出:
为此,我尝试使用“pd.merge”和“if”,但我还没有找到正确的代码... 请问您有什么建议吗?
for i in DF1.Test1:
if DF2.Test1.str.contains(i) == 'True':
ok = pd.merge(DF1, DF2, on= ['Test1'[i]], how='outer')
print(ok)
感谢您的想法 :)
pat = '|'.join(r"{}".format(x) for x in part_string_df[merge_column_lower])- Regressor