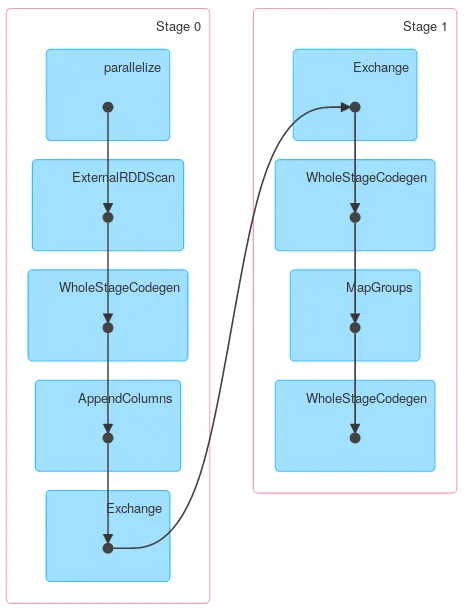
假设我们有一个名为
df的DataFrame,包含以下列:
现在我们想执行一些操作,例如创建一些包含尺寸和宽度数据的DataFrame。名称、姓氏、尺寸、宽度、长度、重量
val df1 = df.groupBy("surname").agg( sum("size") )
val df2 = df.groupBy("surname").agg( sum("width") )
正如您所注意到的,其他列(例如长度)在任何地方都没有使用。Spark是否足够智能,在洗牌阶段之前删除多余的列,还是它们被携带着呢?运行:
val dfBasic = df.select("surname", "size", "width")
在分组之前会以某种方式影响性能吗?