我有一个 Spark Streaming 应用程序和一个 Kafka Streams 应用程序并行运行,用于基准测试。两者都从相同的输入主题消费并写入不同的目标数据库。输入主题有15个分区,Spark Streaming 和 Kafka Streams 都有15个消费者(1:1比例)。此外,事件负载大约为2kb。不确定是否相关,但是 Spark Streaming 的90%执行时间约为9毫秒。Kafka Streams 为12毫秒。每次处理消息时,在我的 Processor 中调用 commit() 方法。
问题在于高峰值。Spark Streaming 可以跟上每秒700个,而 Kafka Streams 只能达到每秒60/70个。我无法超越这一点。请参见下面的图表:(绿线 - Spark Streaming / 蓝线 - Kafka Streams)
处理器代码
问题在于高峰值。Spark Streaming 可以跟上每秒700个,而 Kafka Streams 只能达到每秒60/70个。我无法超越这一点。请参见下面的图表:(绿线 - Spark Streaming / 蓝线 - Kafka Streams)
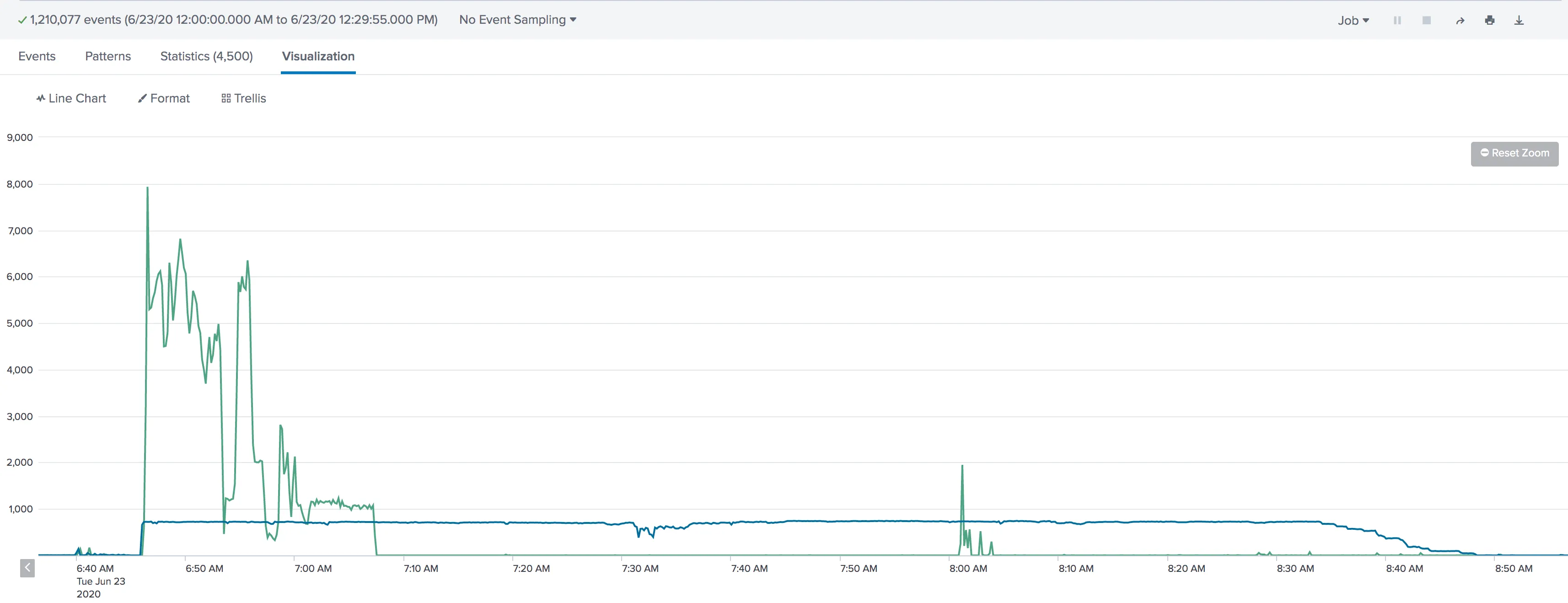
无论我使用 5、10 还是 15 个消费者,我都看到了相同的结果(每秒卡在 70 个事件),这让我认为这与配置有关。我试图通过增加每次提取的记录数和每个分区的最大字节数来调整它们,但没有得到显著的结果。
我知道这些是不同的技术,用于不同的目的,但我想知道在 Kafka Streams 中应该使用什么值来获得更好的吞吐量。
Spark Streaming 配置:
spark.batch.duration=10
spark.streaming.backpressure.enabled=true
spark.streaming.backpressure.initialRate=1000
spark.streaming.kafka.maxRatePerPartition=100
Kafka流配置(所有字节和时间相关)
# Consumer Config
fetch.max.bytes = 52428800
fetch.max.wait.ms = 500
fetch.min.bytes = 1
heartbeat.interval.ms = 3000
max.partition.fetch.bytes = 1048576
max.poll.interval.ms = 300000
max.poll.records = 1000
request.timeout.ms = 30000
enable.auto.commit = false
# StreamsConfig
poll.ms=100
处理器代码
public class KStreamsMessageProcessor extends AbstractProcessor<String, String> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(String key, String payload) {
ResponseEntity responseEntity = null;
try {
// Do Some processing
} catch (final MyException e) {
// Do Some Exception Handling
} finally {
context.forward(UUID.randomUUID().toString(), responseEntity);
context.commit();
}
}
提前感谢!
enable.auto.commit)。我也很惊讶您消耗了70个事件,而不管消费者的数量...我想知道所有记录是否最终都会进入同一个分区,您能验证一下负载是否在所有分区之间平衡吗?查看代码可能也有帮助!也许还要看一下主题配置。 - Augusto