我需要在R数据表中识别和去重记录组(但我想在任何编程语言中都是相同的问题),结构如下:

因此,在示例中,2个红色组是重复的,但是红蓝配对和红棕配对不是。
我的解决方案是将表格转置为宽格式。
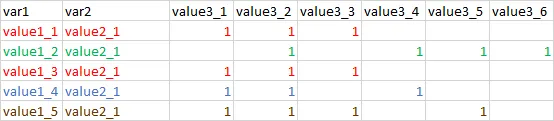
然后执行unique(dt[,var1:=NULL]),再将其转换回长格式(此时我不再需要var1)。
问题在于我的真实表格有165,391,868条记录,这不是一次性任务,而是每周都有类似大小的表格,并且时间有限。
我已经尝试将表格分成块,添加它们,然后执行去重,但第一个转置已经运行了两个多小时!
是否有任何替代方案和更快速的解决方法? 非常感谢!
创建示例表格的代码:
dt <- data.table(
var1=c(
"value1_1",
"value1_1",
"value1_1",
"value1_2",
"value1_2",
"value1_2",
"value1_2",
"value1_3",
"value1_3",
"value1_3",
"value1_4",
"value1_4",
"value1_4",
"value1_5",
"value1_5",
"value1_5",
"value1_5"),
var2=c(
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1",
"value2_1"),
var1=c(
"value3_1",
"value3_2",
"value3_3",
"value3_2",
"value3_4",
"value3_5",
"value3_6",
"value3_1",
"value3_2",
"value3_3",
"value3_1",
"value3_2",
"value3_4",
"value3_1",
"value3_2",
"value3_3",
"value3_5"))
var1值。它们怎么算重复? - Ronak Shah