如何最简单地并行化这段代码?
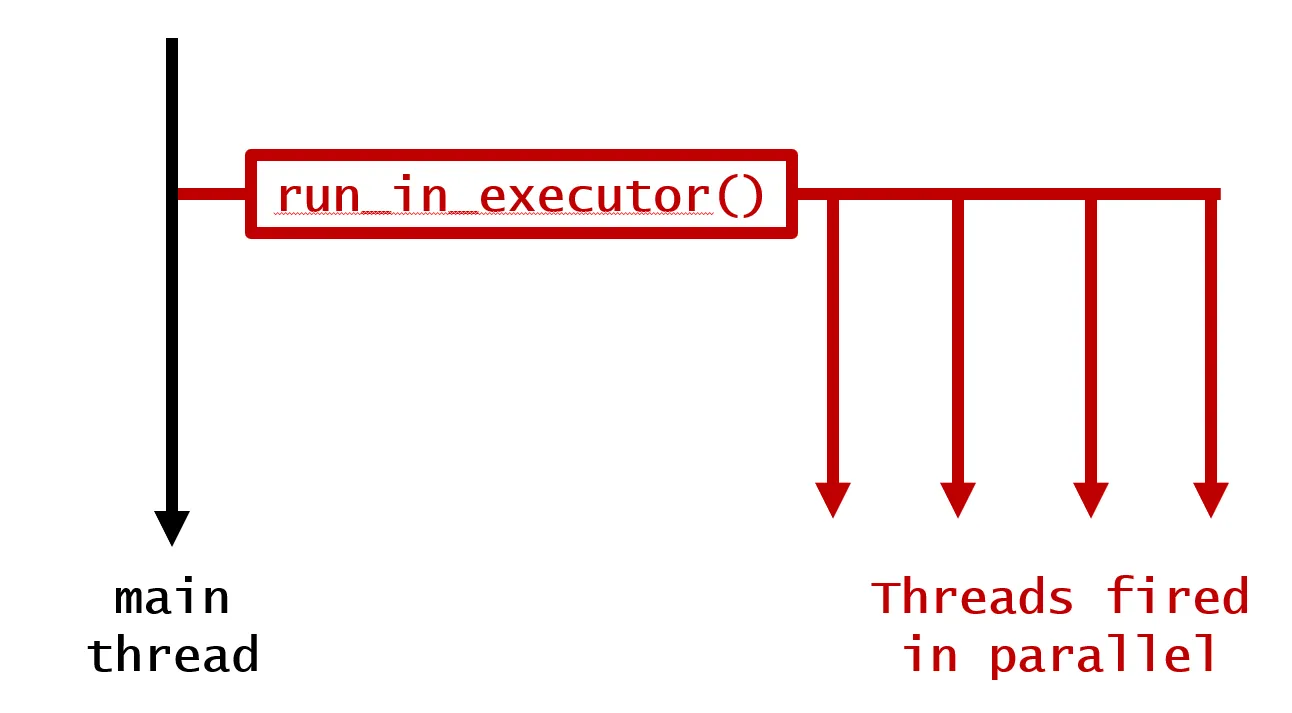
使用concurrent.futures中的PoolExecutor。将原始代码与此进行对比,左右排列。首先,最简洁的方法是使用executor.map:
...
with ProcessPoolExecutor() as executor:
for out1, out2, out3 in executor.map(calc_stuff, parameters):
...
或通过逐个提交每个调用来解决:
...
with ThreadPoolExecutor() as executor:
futures = []
for parameter in parameters:
futures.append(executor.submit(calc_stuff, parameter))
for future in futures:
out1, out2, out3 = future.result()
...
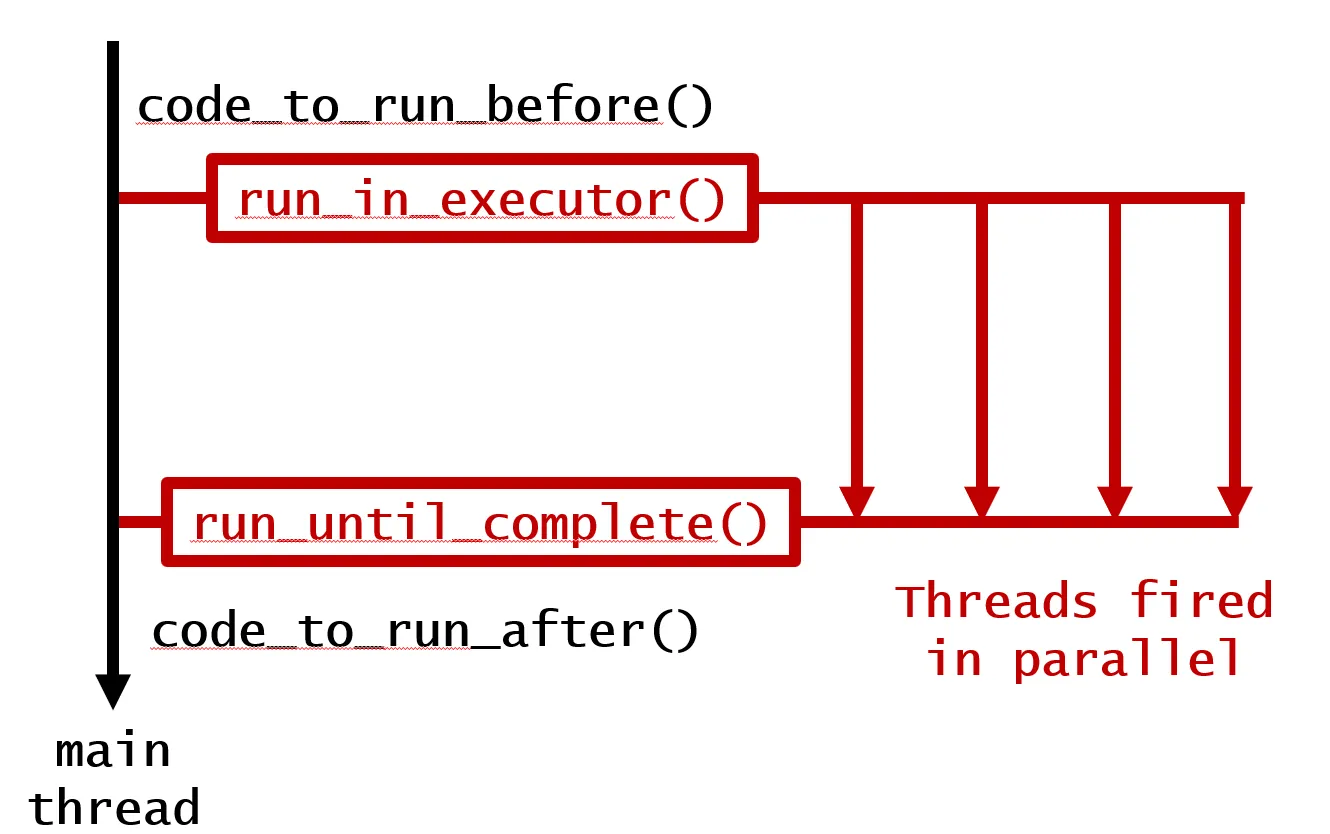
离开上下文会提示执行程序释放资源。
您可以使用线程或进程,并使用完全相同的接口。
一个可用的例子
以下是一个工作示例代码,它将演示以下内容的价值:
将此放入文件 - futuretest.py:
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from time import time
from http.client import HTTPSConnection
def processor_intensive(arg):
def fib(n):
return fib(n-1) + fib(n-2) if n > 1 else n
start = time()
result = fib(arg)
return time() - start, result
def io_bound(arg):
start = time()
con = HTTPSConnection(arg)
con.request('GET', '/')
result = con.getresponse().getcode()
return time() - start, result
def manager(PoolExecutor, calc_stuff):
if calc_stuff is io_bound:
inputs = ('python.org', 'stackoverflow.com', 'stackexchange.com',
'noaa.gov', 'parler.com', 'aaronhall.dev')
else:
inputs = range(25, 32)
timings, results = list(), list()
start = time()
with PoolExecutor() as executor:
for timing, result in executor.map(calc_stuff, inputs):
timings.append(timing), results.append(result)
finish = time()
print(f'{calc_stuff.__name__}, {PoolExecutor.__name__}')
print(f'wall time to execute: {finish-start}')
print(f'total of timings for each call: {sum(timings)}')
print(f'time saved by parallelizing: {sum(timings) - (finish-start)}')
print(dict(zip(inputs, results)), end = '\n\n')
def main():
for computation in (processor_intensive, io_bound):
for pool_executor in (ProcessPoolExecutor, ThreadPoolExecutor):
manager(pool_executor, calc_stuff=computation)
if __name__ == '__main__':
main()
以下是运行 python -m futuretest 的输出结果:
processor_intensive, ProcessPoolExecutor
wall time to execute: 0.7326343059539795
total of timings for each call: 1.8033506870269775
time saved by parallelizing: 1.070716381072998
{25: 75025, 26: 121393, 27: 196418, 28: 317811, 29: 514229, 30: 832040, 31: 1346269}
processor_intensive, ThreadPoolExecutor
wall time to execute: 1.190223217010498
total of timings for each call: 3.3561410903930664
time saved by parallelizing: 2.1659178733825684
{25: 75025, 26: 121393, 27: 196418, 28: 317811, 29: 514229, 30: 832040, 31: 1346269}
io_bound, ProcessPoolExecutor
wall time to execute: 0.533886194229126
total of timings for each call: 1.2977914810180664
time saved by parallelizing: 0.7639052867889404
{'python.org': 301, 'stackoverflow.com': 200, 'stackexchange.com': 200, 'noaa.gov': 301, 'parler.com': 200, 'aaronhall.dev': 200}
io_bound, ThreadPoolExecutor
wall time to execute: 0.38941240310668945
total of timings for each call: 1.6049387454986572
time saved by parallelizing: 1.2155263423919678
{'python.org': 301, 'stackoverflow.com': 200, 'stackexchange.com': 200, 'noaa.gov': 301, 'parler.com': 200, 'aaronhall.dev': 200}
处理器密集型分析
在 Python 中进行处理器密集型计算时,使用 ProcessPoolExecutor 比使用 ThreadPoolExecutor 更高效。
由于全局解释锁(即 GIL),线程无法使用多个处理器,因此每个计算的时间和墙钟时间(经过的实际时间)会更长。
IO 绑定分析
另一方面,在执行 IO 绑定操作时,使用 ThreadPoolExecutor 比使用 ProcessPoolExecutor 更高效。
Python 的线程是真正的操作系统线程。它们可以被操作系统休眠,并在信息到达时重新唤醒。
最后的想法
我怀疑在 Windows 上使用多进程会更慢,因为 Windows 不支持forking,所以每个新进程都需要花费时间来启动。
您可以在多个进程内嵌套多个线程,但建议不要使用多个线程来启动多个进程。
如果在 Python 中遇到重型处理问题,则可以轻松地通过增加进程数量来扩展,但使用线程则不可行。
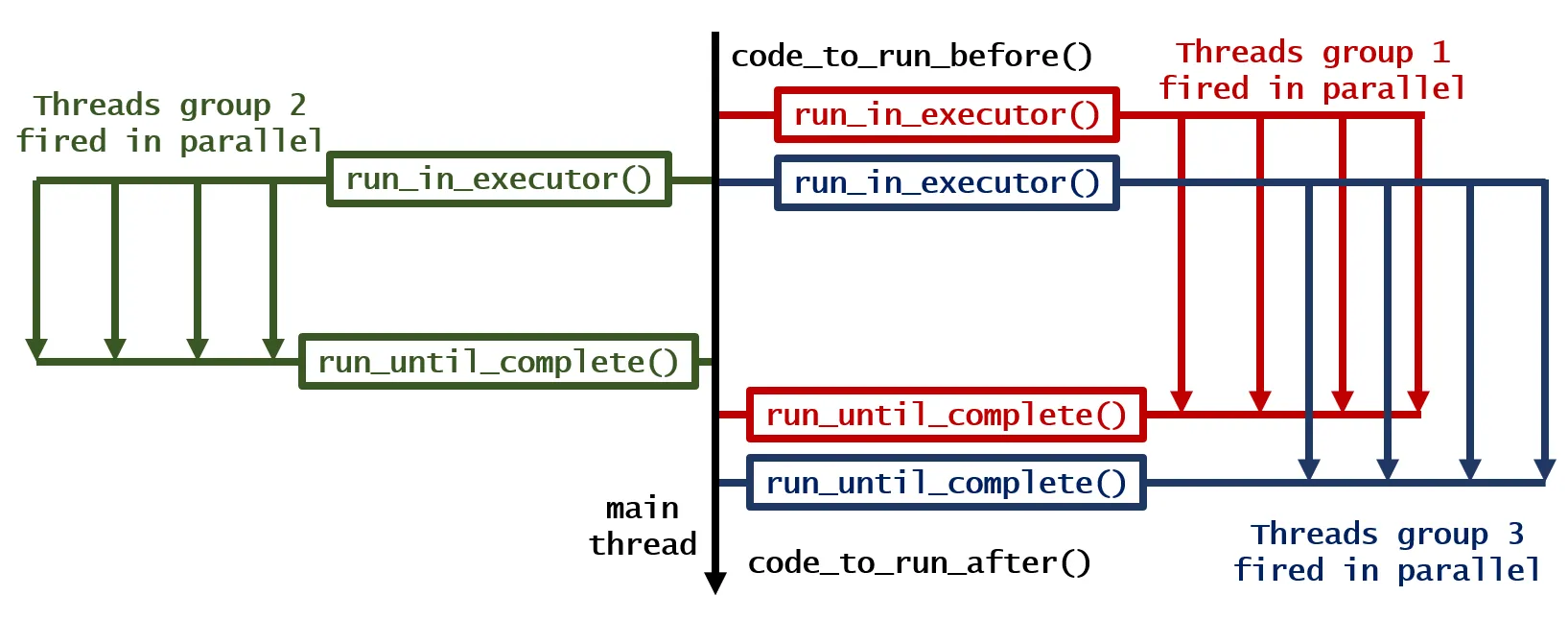
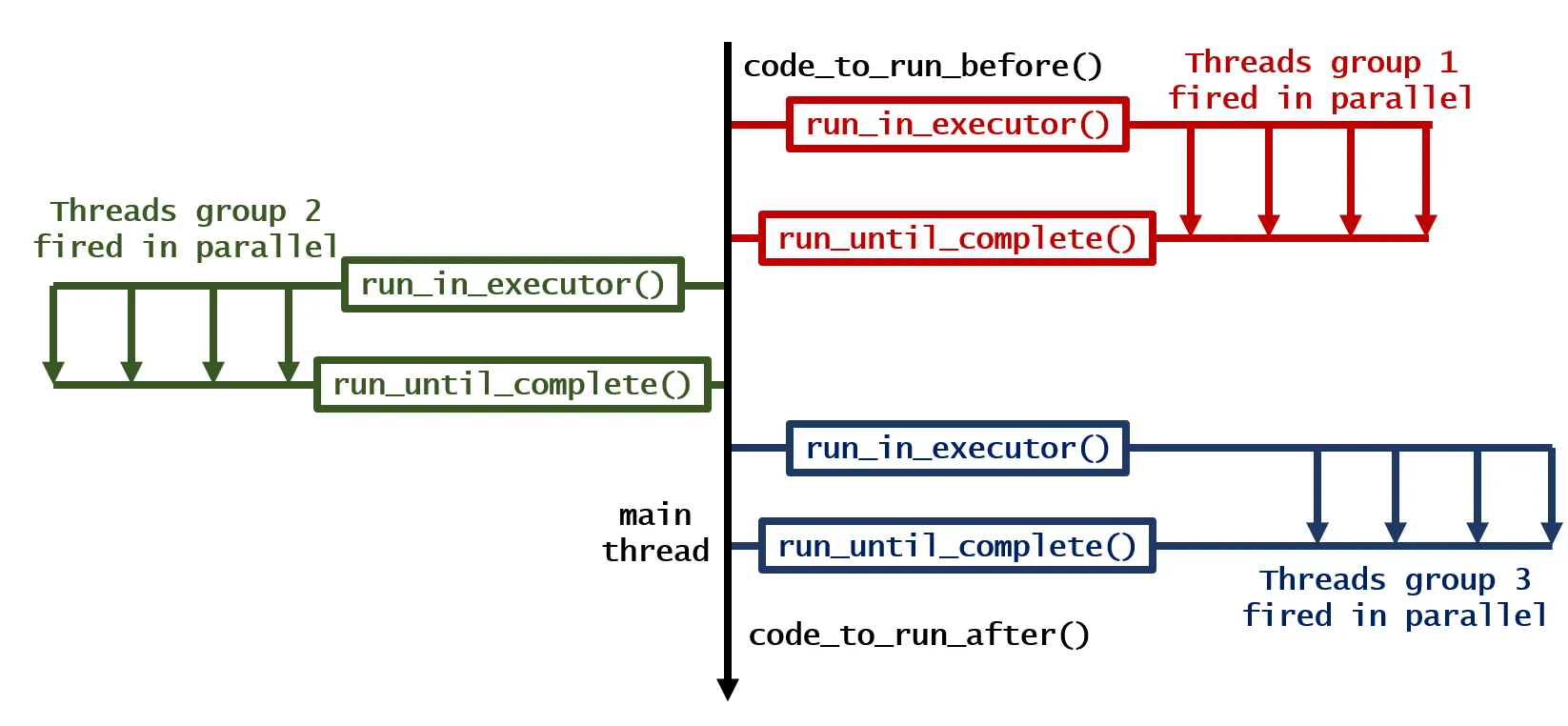
for循环的解决方案还没有被提到 - 这可以通过简单地使用deco包来装饰两个函数来实现。 - 7824238