在C语言中是否有计算反误差函数的方法?
我可以找到<math.h>中的erf(x)用于计算误差函数,但无法找到相应函数进行反运算。
erfinv()或其单精度变体erfinvf()。然而,创建自己的版本并不太困难,我在下面展示了一个具有合理精度和性能的erfinvf()实现。erfinv线性化方法,其中所有方法都基于对数。通常,作者区分从零到大约0.9的反误差函数的主要、相当线性部分和从切换点到单位的尾部部分。在下面的内容中,log()表示自然对数,R()表示有理逼近,P()表示多项式逼近。
A. J. Strecok,“关于误差函数的逆运算计算。” 《计算数学》, Vol. 22, No. 101 (Jan. 1968), pp. 144-158 (在线)
β(x) = (-log(1-x2]))½; erfinv(x) = x · R(x2) [主要部分]; R(x) · β(x) [尾部]
J. M. Blair,C. A. Edwards,J. H. Johnson,“逆误差函数的有理切比雪夫逼近。” 《计算数学》, Vol. 30, No. 136 (Oct. 1976), pp. 827-830 (在线)
M. Giles的文章"Approximating the erfinv function."收录于GPU Computing Gems Jade Edition第109-116页,2011年出版(在线)。ξ = (-log(1-x))-½; erfinv(x) = x · R(x2) [主要部分]; ξ-1 · R(ξ) [尾部]
fma()和fmaf()在C中公开。许多常见的计算平台,例如IBM Power、Arm64、x86-64和GPU都在硬件中提供此操作。在没有硬件支持的情况下,使用fma{f}()可能会使下面的代码速度变慢,因为该操作需要由标准数学库模拟。此外,已知存在功能不正确的FMA模拟(请注意)。#include <math.h>
float my_logf (float);
/* compute inverse error functions with maximum error of 2.35793 ulp */
float my_erfinvf (float a)
{
float p, r, t;
t = fmaf (a, 0.0f - a, 1.0f);
t = my_logf (t);
if (fabsf(t) > 6.125f) { // maximum ulp error = 2.35793
p = 3.03697567e-10f; // 0x1.4deb44p-32
p = fmaf (p, t, 2.93243101e-8f); // 0x1.f7c9aep-26
p = fmaf (p, t, 1.22150334e-6f); // 0x1.47e512p-20
p = fmaf (p, t, 2.84108955e-5f); // 0x1.dca7dep-16
p = fmaf (p, t, 3.93552968e-4f); // 0x1.9cab92p-12
p = fmaf (p, t, 3.02698812e-3f); // 0x1.8cc0dep-9
p = fmaf (p, t, 4.83185798e-3f); // 0x1.3ca920p-8
p = fmaf (p, t, -2.64646143e-1f); // -0x1.0eff66p-2
p = fmaf (p, t, 8.40016484e-1f); // 0x1.ae16a4p-1
} else { // maximum ulp error = 2.35002
p = 5.43877832e-9f; // 0x1.75c000p-28
p = fmaf (p, t, 1.43285448e-7f); // 0x1.33b402p-23
p = fmaf (p, t, 1.22774793e-6f); // 0x1.499232p-20
p = fmaf (p, t, 1.12963626e-7f); // 0x1.e52cd2p-24
p = fmaf (p, t, -5.61530760e-5f); // -0x1.d70bd0p-15
p = fmaf (p, t, -1.47697632e-4f); // -0x1.35be90p-13
p = fmaf (p, t, 2.31468678e-3f); // 0x1.2f6400p-9
p = fmaf (p, t, 1.15392581e-2f); // 0x1.7a1e50p-7
p = fmaf (p, t, -2.32015476e-1f); // -0x1.db2aeep-3
p = fmaf (p, t, 8.86226892e-1f); // 0x1.c5bf88p-1
}
r = a * p;
return r;
}
/* compute natural logarithm with a maximum error of 0.85089 ulp */
float my_logf (float a)
{
float i, m, r, s, t;
int e;
m = frexpf (a, &e);
if (m < 0.666666667f) { // 0x1.555556p-1
m = m + m;
e = e - 1;
}
i = (float)e;
/* m in [2/3, 4/3] */
m = m - 1.0f;
s = m * m;
/* Compute log1p(m) for m in [-1/3, 1/3] */
r = -0.130310059f; // -0x1.0ae000p-3
t = 0.140869141f; // 0x1.208000p-3
r = fmaf (r, s, -0.121484190f); // -0x1.f19968p-4
t = fmaf (t, s, 0.139814854f); // 0x1.1e5740p-3
r = fmaf (r, s, -0.166846052f); // -0x1.55b362p-3
t = fmaf (t, s, 0.200120345f); // 0x1.99d8b2p-3
r = fmaf (r, s, -0.249996200f); // -0x1.fffe02p-3
r = fmaf (t, m, r);
r = fmaf (r, m, 0.333331972f); // 0x1.5554fap-2
r = fmaf (r, m, -0.500000000f); // -0x1.000000p-1
r = fmaf (r, s, m);
r = fmaf (i, 0.693147182f, r); // 0x1.62e430p-1 // log(2)
if (!((a > 0.0f) && (a <= 3.40282346e+38f))) { // 0x1.fffffep+127
r = a + a; // silence NaNs if necessary
if (a < 0.0f) r = ( 0.0f / 0.0f); // NaN
if (a == 0.0f) r = (-1.0f / 0.0f); // -Inf
}
return r;
}
快速且不太精确,容差在+-6e-3之间。该方法基于Sergei Winitzki的"A handy approximation for the error function and its inverse"。
C/C++ 代码:
float myErfInv2(float x){
float tt1, tt2, lnx, sgn;
sgn = (x < 0) ? -1.0f : 1.0f;
x = (1 - x)*(1 + x); // x = 1 - x*x;
lnx = logf(x);
tt1 = 2/(PI*0.147) + 0.5f * lnx;
tt2 = 1/(0.147) * lnx;
return(sgn*sqrtf(-tt1 + sqrtf(tt1*tt1 - tt2)));
}
MATLAB健康检查:
clear all, close all, clc
x = linspace(-1, 1,10000);
% x = 1 - logspace(-8,-15,1000);
a = 0.15449436008930206298828125;
% a = 0.147;
u = log(1-x.^2);
u1 = 2/(pi*a) + u/2; u2 = u/a;
y = sign(x).*sqrt(-u1+sqrt(u1.^2 - u2));
f = erfinv(x); axis equal
figure(1);
plot(x, [y; f]); legend('Approx. erf(x)', 'erf(x)')
figure(2);
e = f-y;
plot(x, e);
MATLAB 绘图:
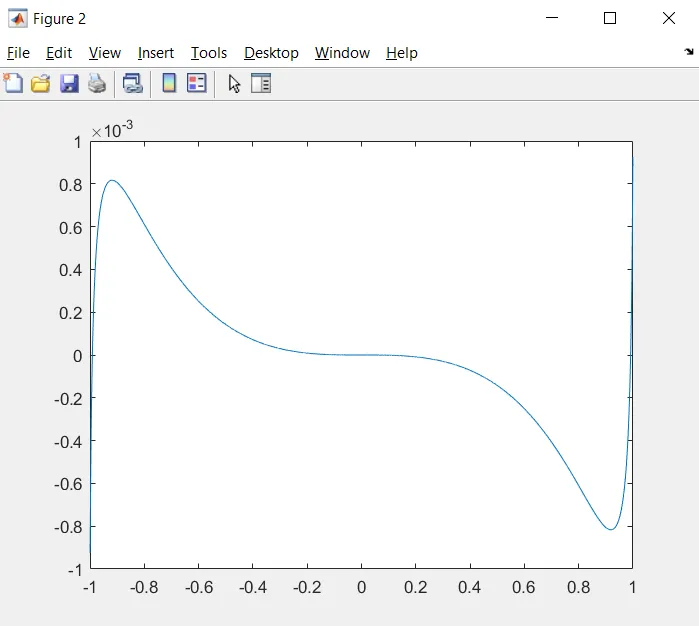
x = 1 - logspace(-8,-15,100);,然后比较两个常数,您将看到原始的 0.147 的稳定性比建议的那个更不发散(即-8e-3与-13e-3)。但实际上这是吹毛求疵,这么微小的等波纹误差是不可能的。我会使用您的常数进行更新。 - nimig18我编写了另一种使用快速收敛的牛顿-拉弗森方法的函数,这是一种迭代方法,用于查找函数的根。它从一个初始猜测开始,然后通过使用函数的导数来迭代地改进猜测。牛顿-拉弗森方法需要函数、其导数、一个初始猜测和一个停止准则。
在这种情况下,我们要找到根的函数是 erf(x) - x。这个函数的导数是 2.0 / sqrt(pi) * exp(-x**2)。初始猜测是输入值 x。停止准则是一个容差值,在这种情况下是 1.0e-16。以下是代码:
/*
============================================
Compile and execute with:
$ gcc inverf.c -o inverf -lm
$ ./inverf
============================================
*/
#include <stdio.h>
#include <math.h>
int main() {
double x, result, fx, dfx, dx, xold;
double tolerance = 1.0e-16;
double pi = 4.0 * atan(1.0);
int iteration, i;
// input value for x
printf("Calculator for inverse error function.\n");
printf("Enter the value for x: ");
scanf("%lf", &x);
// check the input value is between -1 and 1
if (x < -1.0 || x > 1.0) {
printf("Invalid input, x must be between -1 and 1.");
return 0;
}
// initial guess
result = x;
xold = 0.0;
iteration = 0;
// iterate until the solution converges
do {
xold = result;
fx = erf(result) - x;
dfx = 2.0 / sqrt(pi) * exp(-pow(result, 2.0));
dx = fx / dfx;
// update the solution
result = result - dx;
iteration = iteration + 1;
} while (fabs(result - xold) >= tolerance);
// output the result
printf("The inverse error function of %lf is %lf\n", x, result);
printf("Number of iterations: %d\n", iteration);
return 0;
}
Calculator for inverse error function. Enter the value for x: 0.5 The inverse error function of 0.500000 is 0.476936 Number of iterations: 5
还有一个快速而粗略的方法:如果允许较低的精度,那么我将使用反双曲正切函数进行逼近 - 参数通过蒙特卡罗模拟寻找,其中所有随机值都在0.5到1.5的范围内:
p1 = 1.4872301551536515
p2 = 0.5739159012216655
p3 = 0.5803635928651558
atanh( p^( 1 / p3 ) ) / p2 )^( 1 / p1 )
这是通过我的误差函数近似与双曲正切函数的代数重排得出的,其中在1到4之间的x的RMSE误差为0.000367354:
tanh( x^p1 * p2 )^p3