我正在尝试学习使用Python解析HTML,目前遇到了困难——soup.findAll返回了一个空数组,因此有些元素无法被找到。以下是我的代码:
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
headers = {"User-Agent":'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
url = 'https://www.oddsportal.com/matches/tennis/20191114/'
responce = requests.get(url,headers=headers)
soup = BeautifulSoup(responce.text, 'html.parser')
info = soup.findAll('tr', {'class':'odd deactivate'})
print(info)
非常感谢您提供的任何帮助,先行致谢。
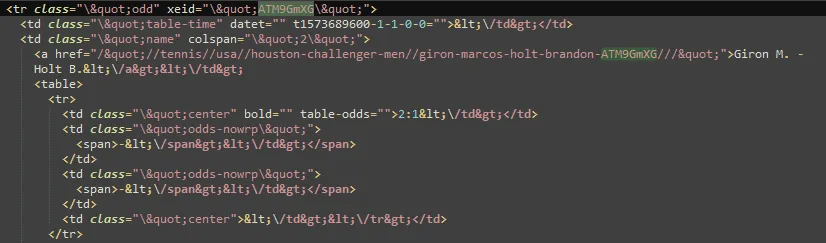
response里面有什么了吗? - BlueSheepTokenresponse.text示例来完成你的[mcve]。 - wwii