简化情况:
我正在开发一个实时应用程序,需要将大约650个对象保存为数组到Redux store中。
该应用程序使用ReactJs-Redux-ImmutableJs-Reselect技术栈。但是我已经确定了减速实际上是将数据保存到Redux store中。
使用ImmutableJs是无关紧要的。我已经创建了有和没有这个框架的POC,并且性能没有改变。
以下代码是我的SearchReducer
const searchReducer = (state = fromJS(defaultState), action) => {
switch(action.type) {
case SEARCHMUSICIAN:
const { searchTerm, results } = action.payload;
return state.set('searchTerm', searchTerm)
.set('foundMusicians', fromJS(results));
default:
return state;
}
};
什么原因导致了减速?Redux在处理大量数据或一次性处理大量数据时是否真的很慢?是否有我忽略的标志或配置可以提高Redux的性能?
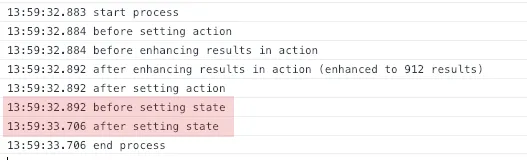
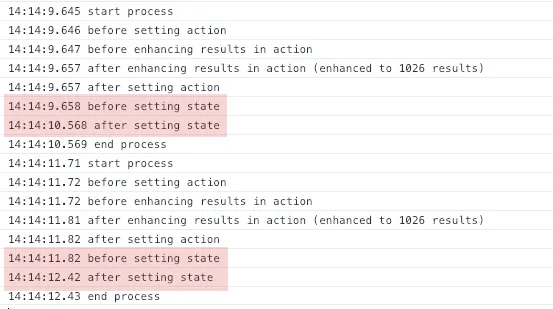
console.time)?这650个对象内部的数据有多大?存储本身并没有做特殊的事情来减慢代码,redux内部的代码非常简单。你是如何测量性能的?你的UI性能可能取决于其他因素,比如redux-connect、PureComponent的使用等等。 - Dominic