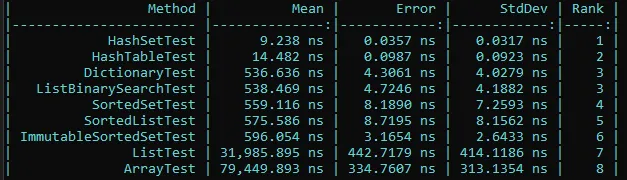
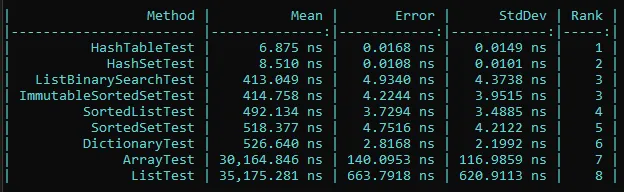
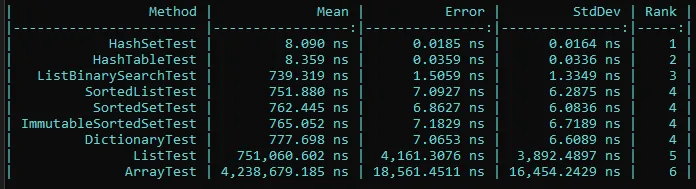
我有60,000个项目需要与20,000个查找列表进行匹配。是否有一种集合对象(例如List,HashTable),它提供了异常快速的Contains()方法?还是我必须编写自己的代码?换句话说,默认的Contains()方法只是扫描每个项目,还是使用更好的搜索算法。
foreach (Record item in LargeCollection)
{
if (LookupCollection.Contains(item.Key))
{
// Do something
}
}
注意。查找列表已经排序。