什么是使用Uvicorn部署FastAPI应用程序和Tiangolo的Gunicorn + Uvicorn容器化的区别?为什么我的结果表明,仅使用Uvicorn部署比Gunicorn + Uvicorn获得更好的结果?
当我在Tiangolo的文档中搜索时,它说:
您可以使用Gunicorn来管理Uvicorn并运行多个并发进程。这样,您就可以得到最佳的并发性和并行性。
从这个说明中,我可以假设使用Gunicorn会获得更好的结果吗?
这是我使用JMeter进行测试的结果。我将我的脚本部署到Google Cloud Run,并且这是结果:
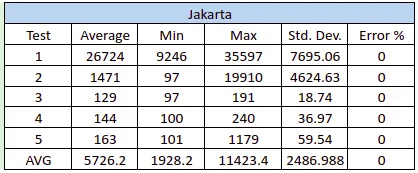
使用Python和Uvicorn:
当我在Tiangolo的文档中搜索时,它说:
您可以使用Gunicorn来管理Uvicorn并运行多个并发进程。这样,您就可以得到最佳的并发性和并行性。
从这个说明中,我可以假设使用Gunicorn会获得更好的结果吗?
这是我使用JMeter进行测试的结果。我将我的脚本部署到Google Cloud Run,并且这是结果:
使用Python和Uvicorn:
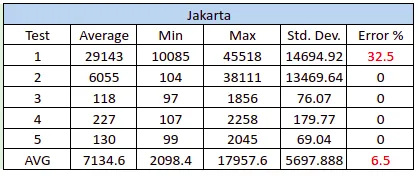
使用Tiangolo的Gunicorn+Uvicorn:
这是我的Python(Uvicorn)Dockerfile:
FROM python:3.8-slim-buster
RUN apt-get update --fix-missing
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y libgl1-mesa-dev python3-pip git
RUN mkdir /usr/src/app
WORKDIR /usr/src/app
COPY ./requirements.txt /usr/src/app/requirements.txt
RUN pip3 install -U setuptools
RUN pip3 install --upgrade pip
RUN pip3 install -r ./requirements.txt --use-feature=2020-resolver
COPY . /usr/src/app
CMD ["python3", "/usr/src/app/main.py"]
这是我的Dockerfile,用于Tiangolo的Gunicorn+Uvicorn:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.8-slim
RUN apt-get update && apt-get install wget gcc -y
RUN mkdir -p /app
WORKDIR /app
COPY ./requirements.txt /app/requirements.txt
RUN python -m pip install --upgrade pip
RUN pip install --no-cache-dir -r /app/requirements.txt
COPY . /app
你可以从Tiangolo的Gunicorn+Uvicorn中看到错误。这是由Gunicorn引起的吗?
已编辑。
所以,在我的情况下,我使用惰性加载方法来加载我的机器学习模型。这是我的类来加载模型。
class MyModelPrediction:
# init method or constructor
def __init__(self, brand):
self.brand = brand
# Sample Method
def load_model(self):
pathfile_model = os.path.join("modules", "model/")
brand = self.brand.lower()
top5_brand = ["honda", "toyota", "nissan", "suzuki", "daihatsu"]
if brand not in top5_brand:
brand = "ex_Top5"
with open(pathfile_model + f'{brand}_all_in_one.pkl', 'rb') as file:
brand = joblib.load(file)
else:
with open(pathfile_model + f'{brand}_all_in_one.pkl', 'rb') as file:
brand = joblib.load(file)
return brand
这是我的API的终端节点。
@router.post("/predict", response_model=schemas.ResponsePrediction, responses={422: schemas.responses_dict[422], 400: schemas.responses_dict[400], 500: schemas.responses_dict[500]}, tags=["predict"], response_class=ORJSONResponse)
async def detect(
*,
# db: Session = Depends(deps.get_db_api),
car: schemas.Car = Body(...),
customer_id: str = Body(None, title='Customer unique identifier')
) -> Any:
"""
Predict price for used vehicle.\n
"""
global list_detections
try:
start_time = time.time()
brand = car.dict()['brand']
obj = MyModelPrediction(brand)
top5_brand = ["honda", "toyota", "nissan", "suzuki", "daihatsu"]
if brand not in top5_brand:
brand = "non"
if usedcar.price_engine_4w[brand]:
pass
else:
usedcar.price_engine_4w[brand] = obj.load_model()
print("Load success")
elapsed_time = time.time() - start_time
print(usedcar.price_engine_4w)
print("ELAPSED MODEL TIME : ", elapsed_time)
list_detections = await get_data_model(**car.dict())
if list_detections is None:
result_data = None
else:
result_data = schemas.Prediction(**list_detections)
result_data = result_data.dict()
except Exception as e: # noqa
raise HTTPException(
status_code=500,
detail=str(e),
)
else:
if result_data['prediction_price'] == 0:
raise HTTPException(
status_code=400,
detail="The system cannot process your request",
)
else:
result = {
'code': 200,
'message': 'Successfully fetched data',
'data': result_data
}
return schemas.ResponsePrediction(**result)
async def和await。如果我们参考之前解释过的tiangolo-gunicorn-uvicorn,应该会很顺利,对吧? - MADFROST