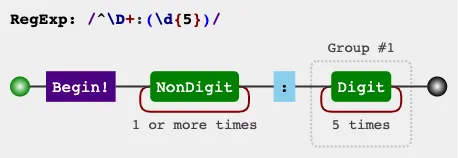
我正在尝试编写一些正则表达式,以便在电子邮件中提取可能的引用。我需要知道如何从特定位置向后查找到第一个空格。如果找到数字,则不希望提取引用。我已经完成了以下工作。我有两个捕获组——“PreRef”和“Ref”。如果“PreRef”包含数字,则不希望找到“Ref”匹配项。到目前为止,我只检查冒号之前的字符是否是数字。
但是这里不行(单词“reference”中有一个数字5):
(?<PreRef>\S+)(?<![\d]):(?<Ref>\d{5})
这里应该找到一个编号为12345的'Ref'匹配项:
This is a reference:12345
但是这里不行(单词“reference”中有一个数字5):
This is not a ref5rence:12345