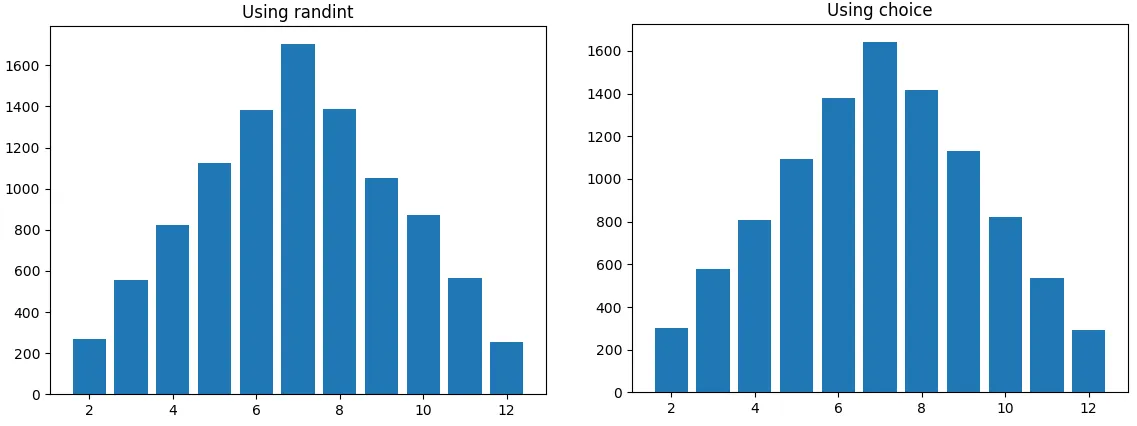
您说得对,您在学生的直方图中观察到的12的数量比掷出12的理论概率要高,但原因并非您所想。
一个实验:
import random
def roll_dice(method):
if method == "choice":
return random.choice([1,2,3,4,5,6]) + random.choice([1,2,3,4,5,6])
else:
return random.randint(1,6) + random.randint(1,6)
def est_prob(n,k,method):
rolls = [roll_dice(method) for _ in range(k)]
return rolls.count(n)/k
def test12(n,k,method):
return sum(1 if est_prob(12,n,method) > 1/36 else 0 for _ in range(k))/k
请注意,
test12(100,10000,"randint")估计基于
randint的100个骰子掷出的直方图过度代表了和为12的概率。
典型运行:
>>> test12(100,10000,"randint")
0.5288
这个结果比50%大得多,而且在统计学上具有显著性(进行10000次试验是估算概率的相当大的次数)。
那么,randint()存在偏差的证据呢?不要急:
>>> test12(100,10000,"choice")
0.5342
使用
random.choice()同样如此。这并不令人惊讶,因为基于100次掷骰子的大部分骰子掷出直方图都会高估12的概率。
当你掷100次骰子时,预期得到的总点数为12的次数是100/36 = 2.78次。但是--你只能观察到整数个12。观察到3个或更多12的概率(从而导致过度表现12的直方图)是P(X >= 3),其中X是具有参数p = 1/36和n = 100的二项式随机变量。可以计算出这个概率。
P(X >= 3) = 1 - P(X<=2)
= 1 - P(0) - P(1) - P(2)
= 1 - 0.0598 - 0.1708 - 0.2416
= 0.5278
因此,约有53%的这样的直方图有“过多”的12,这是您在使用
random.choice()和
random.randint()时都会看到的现象。
似乎您更多地注意到了
randint的情况,并将其解释为偏差(尽管它并不是),并假设这是
randint的缺陷。