是Oracle、MySQL还是他们自己构建的东西?
谷歌使用什么数据库?
388
- john
9
193他想知道 Stack Overflow 使用的数据库堆栈时,会使用 Google 进行查询。 - flybywire
351不要抨击他,我是通过谷歌搜索来到这里的。 - Shawn Mclean
146在谷歌上搜索“谷歌数据库”,排名第一的结果是这个页面,而该页面的第一个评论却建议使用谷歌,这是否更加具有讽刺意味? - Patrick Szalapski
92听起来像是堆栈溢出的情况。 - Thomas
5在搜索之前,我在想谷歌是否会给我正确的答案,但是现在我们开始吧 :P - Abdul Saboor
显示剩余4条评论
8个回答
601
Bigtable
Bigtable是由Google构建的分布式存储系统,用于管理结构化数据,旨在可伸缩至非常大:跨数千个普通服务器的PB级数据。
许多Google项目使用Bigtable存储数据,包括网络索引、Google Earth和Google Finance。这些应用对Bigtable提出了非常不同的要求,无论是数据大小(从URL到网页再到卫星图像),还是延迟要求(从后端批量处理到实时数据服务)。
尽管存在这些不同的需求,但Bigtable已成功为所有这些Google产品提供了灵活高效的解决方案。
一些特点
- 快速且极大规模的DBMS
- 稀疏的分布式多维排序映射,共享行式和列式数据库的特征。
- 设计用于扩展至PB级别
- 可以在数百或数千台机器上运行
- 容易向系统添加更多机器,并在不进行任何重新配置的情况下自动开始利用这些资源
- 每个表具有多个维度(其中一个是时间字段,允许版本控制)
- 表通过分裂成多个Tablet进行了GFS(Google文件系统)优化-沿选择的行拆分为大小约为200MB的Tablet。
架构
BigTable不是关系型数据库,不支持连接操作,也不支持类似SQL的高级查询。每个表都是一个多维稀疏映射。表由行和列组成,每个单元格都有一个时间戳。可以有多个版本的单元格具有不同的时间戳。该时间戳允许执行"选择此Web页面的'n'个版本"或"删除早于特定日期/时间的单元格"等操作。
为了管理庞大的表格,Bigtable在行边界处分割表格并将它们保存为片段。一个片段大约为200MB,每台机器可保存约100个片段。这种设置允许来自单个表的片段分布在许多服务器之间。它还允许进行精细的负载平衡。如果一个表正在接收许多查询,它可以卸载其他片段或将忙碌的表移动到另一台不那么忙碌的机器上。另外,如果一台机器出现问题,一个片段可能会分散在许多其他服务器上,以便对任何给定机器的性能影响最小化。
表格以不可变的SSTables和日志尾部(每台机器一个日志)存储。当机器耗尽系统内存时,它使用Google专有的压缩技术(BMDiff和Zippy)压缩某些片段。小型压实只涉及几个片段,而大型压实涉及整个表格系统并恢复硬盘空间。
Bigtable片段的位置存储在单元格中。任何特定片段的查找由三层系统处理。客户端获取META0表的指针,其中只有一个。META0表跟踪许多META1片段的位置,这些片段包含正在查找的片段的位置。META0和META1都大量使用预取和缓存来最小化系统瓶颈。
实现
BigTable是建立在Google文件系统(GFS)之上的,GFS用作日志和数据文件的后备存储。 GFS为SSTables提供可靠的存储,这是一种用于持久化表格数据的Google专有文件格式。
BigTable重度使用的另一个服务是高可用性、可靠的分布式锁服务Chubby。 Chubby允许客户端获取锁,并可能将其与一些元数据关联起来,客户端可以通过向Chubby发送保持活动消息来续订锁。锁存储在类似文件系统的分层命名结构中。
Bigtable系统中有三种主要的服务器类型:
- Master服务器:将tablets分配给tablet服务器,跟踪tablets的位置并根据需要重新分配任务。
- Tablet服务器:处理tablets的读写请求,并在超出大小限制(通常为100MB-200MB)时拆分tablets。如果一个tablet服务器失败,则100个tablet服务器各接管1个新的tablet并恢复系统。
- Lock服务器:Chubby分布式锁服务的实例。BigTable内的许多操作都需要获取锁,包括打开用于写入的tablets,确保同一时间最多只有一个活动Master以及访问控制检查。
Google研究论文中的示例:
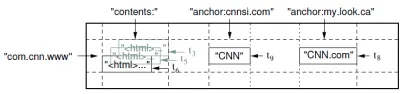
存储Web页面的示例表格的一部分。行名称是反转的URL。内容列族包含页面内容,锚点列族包含引用页面的任何锚点的文本。CNN主页被体育画报和MY-look主页引用,因此该行包含名为anchor:cnnsi.com和anchor:my.look.ca的列。每个锚点单元格只有一个版本; 内容列有三个版本,在时间戳t3、t5和t6处。
API
BigTable的典型操作包括创建和删除表格和列族、写入数据以及从一行中删除列。BigTable通过API向应用程序开发人员提供这些功能。虽然在行级别支持事务,但不支持跨多个行键。
以下是研究论文PDF链接。
在这里,您可以找到视频链接,该视频展示了Google的Jeff Dean在华盛顿大学的演讲中,讨论了Bigtable内容存储系统的使用情况。
- splattne
5
5有人知道这个是从零开始建造的还是基于某个产品吗?我听说过谷歌曾经使用过Oracle,但他们放弃了它,因为他们需要一些Oracle不会或不允许他们进行的修改。我会尝试获取链接。 - OscarRyz
5这是从零开始的,就像他们其他的核心竞争力一样(如Web服务器、GFS等)。 - Matt J
5我正在寻找有关压缩算法(BMDiff和Zippy)的信息,并发现现在Zippy被称为Snappy,并且已经发布在Google Code上:http://code.google.com/p/snappy/。 - helios
7现在他们使用Spanner,这是BigTable的继任者。 - deltonio2
所以,它看起来类似于nosql数据库,如Mongodb或Marklogic。 - stuckedoverflow
36
Spanner 是 Google 的全球分布式关系数据库管理系统(RDBMS),是 BigTable 的后继者。Google声称它不是一个纯粹的关系系统,因为每个表必须有一个主键。
这里是论文链接。
Spanner 是 Google 的可扩展、多版本、全球分布式和同步复制的数据库。它是第一个在全球范围内分发数据并支持外部一致性分布式事务的系统。本文描述了 Spanner 的结构、功能集、各种设计决策的基本原理以及公开暴露时钟不确定性的新型时间 API。此 API 及其实现对于支持外部一致性和各种强大的功能至关重要:过去非阻塞读取、无锁只读事务和全局原子模式更改。
Google 发明的另一个数据库是 Megastore。以下是摘要:
Megastore 是一种存储系统,旨在满足当今的交互式在线服务的要求。Megastore以一种新颖的方式将NoSQL数据存储器的可扩展性与传统RDBMS的便捷性结合在一起,并提供强有力的一致性保证和高可用性。我们在数据的细粒度分区中提供完全可串行化的 ACID 语义。这种分区使我们能够在广域网上同步复制每个写入,并支持数据中心之间的无缝故障转移。本文描述了Megastore的语义和复制算法。它还描述了我们支持使用 Megastore 构建的各种 Google 生产服务的经验。
- user
4
很遗憾Spanner是一个闭源项目。根据描述,我也很想在我的项目中使用它。 - Mikko Rantalainen
2@MikkoRantalainen 你可能想要查看Apache Hadoop生态系统或CockroachDB(尽管Cockroach处于alpha版本)。 - dualed
谢谢,CockroachDB看起来很有趣。我必须测试一下它的性能如何。功能看起来就是我想要的东西。 - Mikko Rantalainen
1自2017年起,Spanner已经在Google Cloud上面向所有人提供使用:https://cloud.google.com/spanner/ - Miscreant
19
正如其他人提到的那样,谷歌使用一种自主开发的解决方案称为BigTable,并发布了几篇介绍它在现实世界中应用的论文。
Apache团队有一个实现这些论文中所述思想的项目,叫做HBase。HBase是更大的Hadoop项目的一部分,根据他们网站上的说法 "是一个软件平台,可以轻松编写和运行处理大量数据的应用程序。" 他们的一些基准测试结果相当令人印象深刻。他们的网站是 http://hadoop.apache.org。
- EvilRyry
1
链接不存在,返回404错误。 - Shivam Jha
14
虽然 Google 在所有主要应用程序中都使用 BigTable,但他们也使用 MySQL来处理其他(可能次要的)应用程序。
- mausch
2
4@smoothdeveloper的链接已失效,可以在这里阅读存档副本:http://web.archive.org/web/20071102233627/http://xooglers.blogspot.com/2005/12/lets-get-real-database.html - josh3736
然而,谷歌不再是MySQL客户名单中的一员... - S. Liu
9
而且,了解BigTable不是关系型数据库(如MySQL),而是一个具有非常不同特性的巨大(分布式)哈希表可能也很方便。您可以在Google AppEngine平台上自己玩弄(有限版本)的BigTable。
除了上面提到的Hadoop之外,还有许多其他实现试图解决与BigTable相同的问题(可扩展性,可用性)。我昨天看到了一篇很好的博客文章,列出了其中大部分这里。
除了上面提到的Hadoop之外,还有许多其他实现试图解决与BigTable相同的问题(可扩展性,可用性)。我昨天看到了一篇很好的博客文章,列出了其中大部分这里。
- Koen Bok
7
谷歌主要使用Bigtable。
Bigtable是一种分布式存储系统,用于管理结构化数据,并设计为可扩展到非常大的规模。
有关更多信息,请从此处下载文档。
谷歌还在一些应用程序中使用Oracle和MySQL数据库。
非常感谢您提供的任何其他信息。
- Suresh Kumar Amrani
2
18谷歌也使用Oracle - 需要参考资料。 - user
@user https://cloud.google.com/sql/docs?如果开发人员可以使用MySQL,那么Google至少必须创建一个将MySQL和Bigtable进行转换的“数据库翻译器”。 - user3139831
1
Google服务具有多语言持久性架构。大部分服务如YouTube,Google搜索,Google Analytics等都利用BigTable。搜索服务最初使用MapReduce作为其索引基础设施,但后来在Caffeine发布期间转向了BigTable。
Google Cloud数据存储在Google内部和外部用户中已经拥有100多个应用程序。 Gmail,Picasa,Google日历,Android市场和AppEngine等应用程序使用Cloud Datastore和Megastore。
Google Trends使用MillWheel进行流处理。 Google Ads最初使用MySQL,后来迁移到F1 DB-一种自定义编写的分布式关系数据库。 Youtube使用带有Vitess的MySQL。谷歌通过Google文件系统在商品服务器上存储数百亿字节的数据。
来源:Google数据库:Google服务如何存储PB-EB级别的数据? YouTube数据库-它如何在不耗尽存储空间的情况下存储如此多的视频?
Google Cloud数据存储在Google内部和外部用户中已经拥有100多个应用程序。 Gmail,Picasa,Google日历,Android市场和AppEngine等应用程序使用Cloud Datastore和Megastore。
Google Trends使用MillWheel进行流处理。 Google Ads最初使用MySQL,后来迁移到F1 DB-一种自定义编写的分布式关系数据库。 Youtube使用带有Vitess的MySQL。谷歌通过Google文件系统在商品服务器上存储数百亿字节的数据。
来源:Google数据库:Google服务如何存储PB-EB级别的数据? YouTube数据库-它如何在不耗尽存储空间的情况下存储如此多的视频?
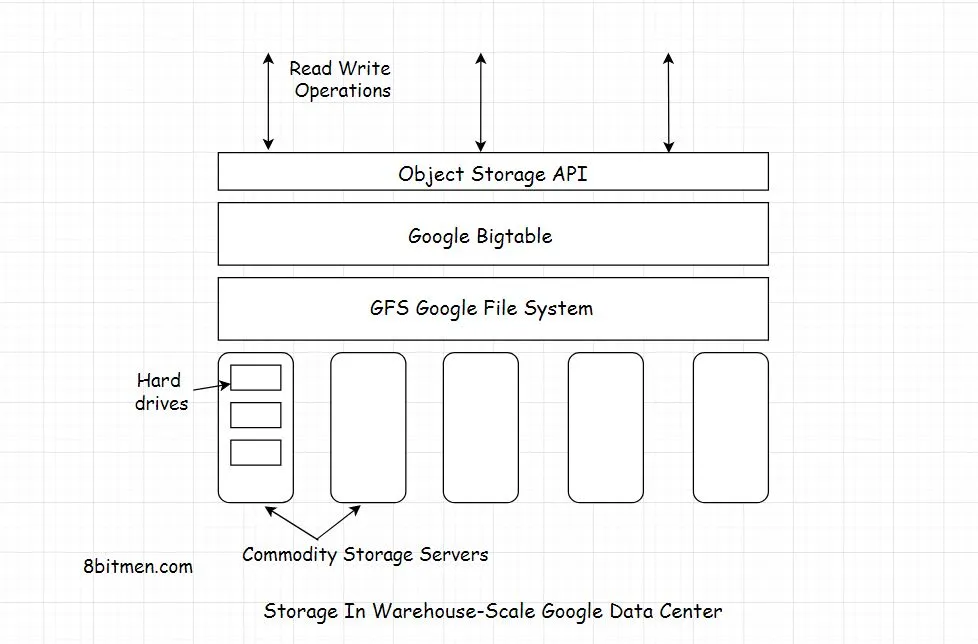
- underdog
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接