是的,有时候type和其他程序会输出乱码,有时候不会,这让人感到沮丧。
首先,Unicode字符只有在当前控制台字体包含这些字符时才能显示。因此,使用TrueType字体(如Lucida Console)而不是默认的Raster Font。
但是,如果控制台字体不包含您要显示的字符,则会看到问号而不是乱码。当您看到乱码时,除了字体设置之外,还有更多的问题。
当程序使用标准C库I/O函数(如printf)时,程序的输出编码必须与控制台的输出编码匹配,否则会出现乱码。 chcp显示并设置当前代码页。所有使用标准C库I/O函数的输出都被视为在chcp显示的代码页中。
将程序的输出编码与控制台的输出编码匹配可以通过两种不同的方式实现:
然而,使用Win32 API的程序可以直接使用
WriteConsoleW将UTF-16LE字符串写入控制台。这是在不设置代码页的情况下获得正确输出的唯一方法。即使使用该函数,如果字符串最初不是UTF-16LE编码,则Win32程序必须向
MultiByteToWideChar传递正确的代码页。此外,如果程序的输出被重定向,则
WriteConsoleW将无法正常工作;在这种情况下需要进行更多的操作。
type 命令有时会起作用,因为它检查每个文件的开头是否有 UTF-16LE 字节顺序标记 (BOM),即字节 0xFF 0xFE。如果发现这样的标记,则无论当前代码页如何,它都将使用 WriteConsoleW 显示文件中的 Unicode 字符。但是,当 type 任何没有 UTF-16LE BOM 的文件或使用任何不调用 WriteConsoleW 的非 ASCII 字符命令时,您需要设置控制台代码页和程序输出编码以匹配。
我该如何找到这个答案呢?
这里有一个包含Unicode字符的测试文件:
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
这是一个打印测试文件在许多不同Unicode编码下的Java程序。它可以使用任何编程语言; 它只会将ASCII字符或编码字节打印到
stdout。
import java.io.*;
public class Foo {
private static final String BOM = "\ufeff";
private static final String TEST_STRING
= "ASCII abcde xyz\n"
+ "German äöü ÄÖÜ ß\n"
+ "Polish ąęźżńł\n"
+ "Russian абвгдеж эюя\n"
+ "CJK 你好\n";
public static void main(String[] args)
throws Exception
{
String[] encodings = new String[] {
"UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE" };
for (String encoding: encodings) {
System.out.println("== " + encoding);
for (boolean writeBom: new Boolean[] {false, true}) {
System.out.println(writeBom ? "= bom" : "= no bom");
String output = (writeBom ? BOM : "") + TEST_STRING;
byte[] bytes = output.getBytes(encoding);
System.out.write(bytes);
FileOutputStream out = new FileOutputStream("uc-test-"
+ encoding + (writeBom ? "-bom.txt" : "-nobom.txt"));
out.write(bytes);
out.close();
}
}
}
}
默认代码页的输出?
完全是垃圾!
Z:\andrew\projects\sx\1259084>chcp
Active code page: 850
Z:\andrew\projects\sx\1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
= bom
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
== UTF-16LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
= bom
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
== UTF-16BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
== UTF-32LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
== UTF-32BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
然而,如果我们键入已保存的文件,它们包含与在控制台上打印的完全相同的字节。
Z:\andrew\projects\sx\1259084>type *.txt
uc-test-UTF-16BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16LE-bom.txt
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
uc-test-UTF-16LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
uc-test-UTF-32BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32LE-bom.txt
A S C I I a b c d e x y z
G e r m a n ä ö ü Ä Ö Ü ß
P o l i s h ą ę ź ż ń ł
R u s s i a n а б в г д е ж э ю я
C J K 你 好
uc-test-UTF-32LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
uc-test-UTF-8-bom.txt
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
uc-test-UTF-8-nobom.txt
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
唯一有效的是带有BOM的UTF-16LE文件,通过type打印到控制台。
如果我们使用除type之外的任何方式来打印文件,我们会得到垃圾数据:
Z:\andrew\projects\sx\1259084>copy uc-test-UTF-16LE-bom.txt CON
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
1 file(s) copied.
从
copy CON 无法正确显示Unicode的事实中,我们可以得出结论,
type 命令具有检测文件开头的UTF-16LE BOM的逻辑,并使用特殊的Windows API打印它。
当
type 命令输出文件时,在调试器中打开
cmd.exe,我们可以看到这一点。
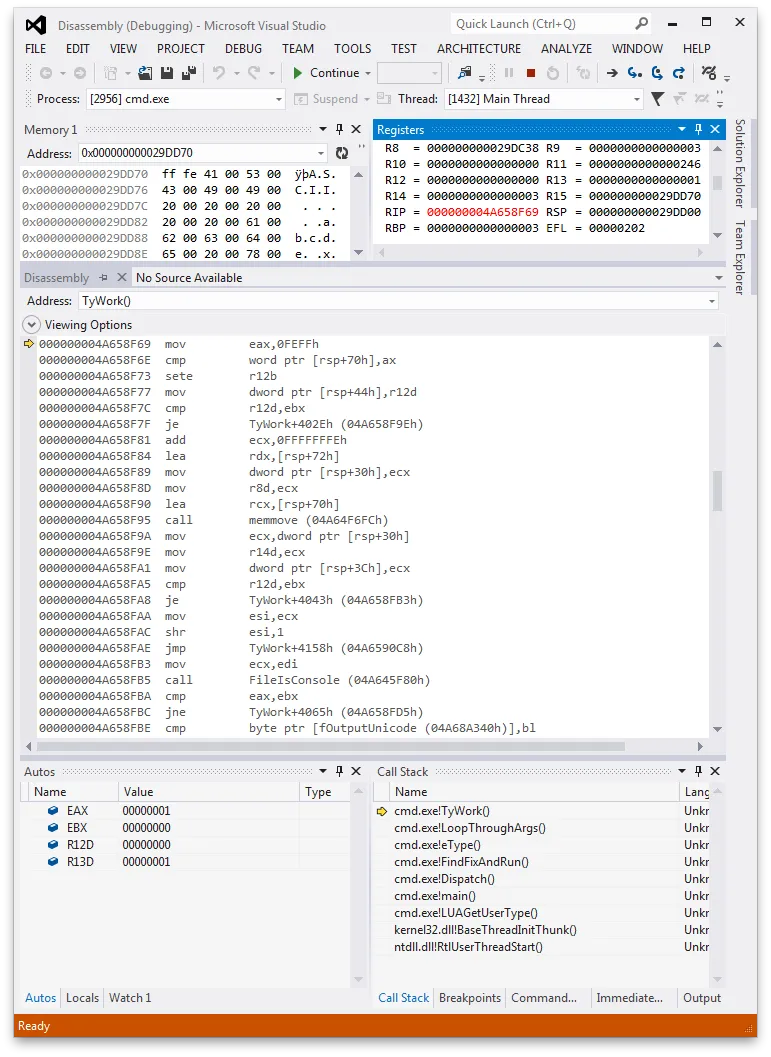
在打开文件后,type 会检查是否存在 0xFEFF 的 BOM,也就是以小端方式表示的字节 0xFF 0xFE。如果存在这样的 BOM,则 type 设置一个内部的 fOutputUnicode 标志。稍后会检查此标志来决定是否调用 WriteConsoleW。
但这是唯一使 type 输出 Unicode 的方法,而且仅适用于具有 BOM 并使用 UTF-16LE 编码的文件。对于所有其他文件以及没有特殊代码处理控制台输出的程序,您的文件将根据当前代码页进行解释,并可能显示为乱码。
您可以像下面这样在自己的程序中模拟 type 输出 Unicode 到控制台:
#include <stdio.h>
#define UNICODE
#include <windows.h>
static LPCSTR lpcsTest =
"ASCII abcde xyz\n"
"German äöü ÄÖÜ ß\n"
"Polish ąęźżńł\n"
"Russian абвгдеж эюя\n"
"CJK 你好\n";
int main() {
int n;
wchar_t buf[1024];
HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);
n = MultiByteToWideChar(CP_UTF8, 0,
lpcsTest, strlen(lpcsTest),
buf, sizeof(buf));
WriteConsole(hConsole, buf, n, &n, NULL);
return 0;
}
这个程序可以在Windows控制台上使用默认代码页打印Unicode。
对于示例Java程序,我们可以通过手动设置代码页来获得一些正确的输出,尽管输出以奇怪的方式被搞乱:
Z:\andrew\projects\sx\1259084>chcp 65001
Active code page: 65001
Z:\andrew\projects\sx\1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
ж эюя
CJK 你好
你好
好
�
= bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
еж эюя
CJK 你好
你好
好
�
== UTF-16LE
= no bom
A S C I I a b c d e x y z
…
然而,一个设置了Unicode UTF-8代码页的C程序:
#include <stdio.h>
#include <windows.h>
int main() {
int c, n;
UINT oldCodePage;
char buf[1024];
oldCodePage = GetConsoleOutputCP();
if (!SetConsoleOutputCP(65001)) {
printf("error\n");
}
freopen("uc-test-UTF-8-nobom.txt", "rb", stdin);
n = fread(buf, sizeof(buf[0]), sizeof(buf), stdin);
fwrite(buf, sizeof(buf[0]), n, stdout);
SetConsoleOutputCP(oldCodePage);
return 0;
}
是否有正确的输出:
Z:\andrew\projects\sx\1259084>.\test
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
这则故事的寓意是什么?
type 命令可以打印带有 BOM 的 UTF-16LE 文件,无论当前代码页是什么。- Win32 程序可以通过
WriteConsoleW 输出 Unicode 到控制台。
- 其他程序可以设置代码页并相应地调整输出编码,在控制台上打印 Unicode,无论程序启动时的代码页是什么。
- 对于其他情况,你将不得不使用
chcp 并且可能仍然会得到奇怪的输出。
WriteFile报告写入的字符数而不是字节数,因此带缓冲的写入器会根据非ASCII字符的数量多次重试“剩余”的字节。在65001中,由于在调用WideCharToMultiByte时假定每个UTF-16代码有1个ANSI字节,因此在conhost.exe中读取非ASCII字符会失败。 - Eryk SunGetStdHandle(STD_OUTPUT_HANDLE)和 Cstdout是控制台句柄。在实践中,要测试是否为控制台,请检查GetConsoleMode是否成功。同时,不要使用 C 运行时的_isatty函数来检查低 I/O 文件描述符是否是控制台;那只是检查字符模式设备,其中包括了NUL等其他内容。相反,调用_get_osfhandle并直接检查句柄。 - Eryk Sun