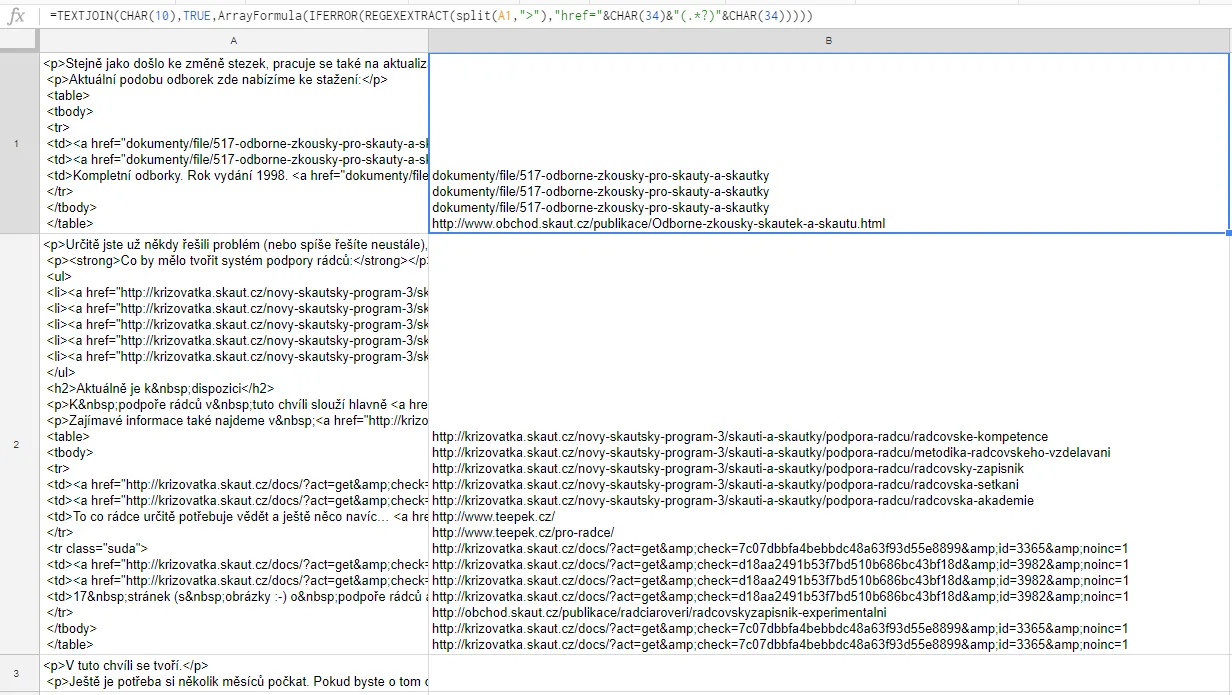
我在我的Google电子表格中有大约3000行,每一行包含有关我们网站上一篇文章的数据。在一列(例如A: A)中存储了HTML格式化文本。我需要从此列中提取所有
我尝试使用
我知道这不是从HTML中获取任何内容的正确方法。是否有另一种方法可以从单个单元格中的HTML文本中提取这些值?
示例数据链接:Google电子表格 非常感谢!我真的很新,对脚本、解析等也不熟悉。
href = ""属性内的URL,并稍后使用它们(可以是数组或以逗号或空格分隔的文本字符串,位于B列中)。我尝试使用
REGEXTRACT公式,但它只给我第一个结果。然后我尝试使用REGEXREPLACE,但我无法编写正确的表达式来仅获取URL链接。我知道这不是从HTML中获取任何内容的正确方法。是否有另一种方法可以从单个单元格中的HTML文本中提取这些值?
示例数据链接:Google电子表格 非常感谢!我真的很新,对脚本、解析等也不熟悉。