我可以使用哪些并行算法来从给定的集合中生成随机排列? 特别是对于适用于CUDA的论文或提议将会很有帮助。
这个问题的顺序版本是 Fisher-Yates shuffle。
例如:
假设S={1, 2, ..., 7}是源索引的集合。 目标是并行生成n个随机排列。 每个随机排列恰好包含源索引集合中的每个元素,例如{7, 6, ..., 1}。
Fisher-Yates洗牌算法可以并行化。例如,4个并发工作器只需要3次迭代就可以洗牌8元素的向量。在第一次迭代中,它们交换0<->1、2<->3、4<->5、6<->7;在第二次迭代中,它们交换0<->2、1<->3、4<->5、6<->7;在最后一次迭代中,它们交换0<->4、1<->5、2<->6、3<->7。
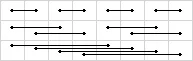
这可以很容易地实现为CUDA __device__代码(受标准最小/最大缩减启发):
const int id = threadIdx.x;
__shared__ int perm_shared[2 * BLOCK_SIZE];
perm_shared[2 * id] = 2 * id;
perm_shared[2 * id + 1] = 2 * id + 1;
__syncthreads();
unsigned int shift = 1;
unsigned int pos = id * 2;
while(shift <= BLOCK_SIZE)
{
if (curand(&curand_state) & 1) swap(perm_shared, pos, pos + shift);
shift = shift << 1;
pos = (pos & ~shift) | ((pos & shift) >> 1);
__syncthreads();
}
这里省略了curand初始化代码,并且方法swap(int *p, int i, int j)交换值p[i]和p[j]。
请注意,上面的代码做出了以下假设:
__shared__内存要生成多个排列,建议利用不同的CUDA块。如果目标是对7个元素进行排列(如原始问题中所述),那么我认为在单个线程中执行会更快。
val = {1,2,...,7,1,2,...,7,....,1,2,...7}
val_keys = {0,0,0,0,0,0,0,1,1,1,1,1,1,2,2,2,...., n,n,n}
U = {0.24, 0.1, .... , 0.83}
然后您可以对val、val_keys进行zip迭代,并根据U对它们进行排序:
http://codeyarns.com/2011/04/04/thrust-zip_iterator/
val和val_keys都会乱序,因此您需要使用thrust :: stable_sort_by_key()将它们重新组合,以确保如果val [i]和val [j]都属于key [k]并且val [i]在随机排序中先于val [j],则在最终版本中val [i]仍应先于val [j]。如果一切顺利,val_keys应该看起来与之前完全相同,但val应反映洗牌。
对于大型数据集,使用随机键的向量进行排序原语可能已经足够满足您的需求。首先,设置一些向量:
const int N = 65535;
thrust:device_vector<uint16_t> d_cards(N);
thrust:device_vector<uint16_t> d_keys(N);
thrust::sequence(d_cards.begin(), d_cards.end());
然后,每次您想要洗牌 d_cards 时,请调用一对:
thrust::tabulate(d_keys.begin(), d_keys.end(), PRNFunc(rand()*rand());
thrust::sort_by_key(d_keys.begin(), d_keys.end(), d_cards.begin());
// d_cards now freshly shuffled
随机密钥是由一个函数对象生成的,该函数对象使用一个种子(在主机代码中计算并在启动时复制到内核)和一个密钥编号(在线程创建时传递给表格):
struct PRNFunc
{
uint32_t seed;
PRNFunc(uint32_t s) { seed = s; }
__device__ __host__ uint32_t operator()(uint32_t kn) const
{
thrust::minstd_rand randEng(seed);
randEng.discard(kn);
return randEnd();
}
};
我发现如果我能够找出如何缓存thrust :: sort_by_key内部执行的分配,性能可能会提高(大约30%)。
欢迎任何更正或建议。
thrust::permutation_iterator怎么样?但是,这需要你编写自己的重新索引方案。 - Recker