我正在通过C代码在CUDA(Fermi GPU)中进行数据预取。CUDA参考手册讨论了在PTX级别代码而不是C级别代码中的预取。
有没有人能够提供有关通过CUDA代码(cu文件)进行预取的文档或其他相关信息。任何帮助都将不胜感激。
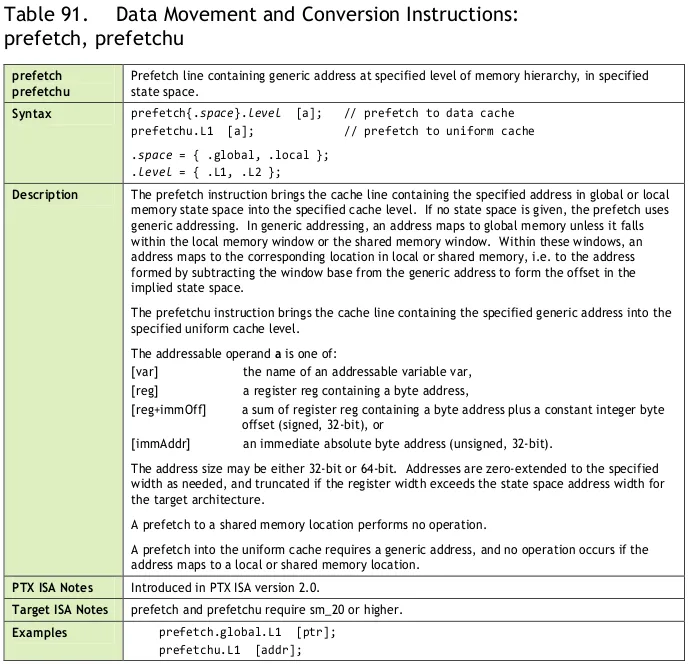 您可以将PTX指令嵌入到CUDA内核中。以下是来自NVIDIA文档的一个小示例:
您可以将PTX指令嵌入到CUDA内核中。以下是来自NVIDIA文档的一个小示例:__device__ int cube (int x)
{
int y;
asm("{\n\t" // use braces for local scope
" .reg .u32 t1;\n\t" // temp reg t1,
" mul.lo.u32 t1, %1, %1;\n\t" // t1 = x * x
" mul.lo.u32 %0, t1, %1;\n\t" // y = t1 * x
"}"
: "=r"(y) : "r" (x));
return y;
}
__device__ void prefetch_l1 (unsigned int addr)
{
asm(" prefetch.global.L1 [ %1 ];": "=r"(addr) : "r"(addr));
}
注意:您需要具有计算能力为2.0或更高的GPU才能进行预取。请相应地传递适当的编译标志-arch=sm_20
根据这篇帖子,以下是不同缓存预取技术的代码:
#define DEVICE_STATIC_INTRINSIC_QUALIFIERS static __device__ __forceinline__
#if (defined(_MSC_VER) && defined(_WIN64)) || defined(__LP64__)
#define PXL_GLOBAL_PTR "l"
#else
#define PXL_GLOBAL_PTR "r"
#endif
DEVICE_STATIC_INTRINSIC_QUALIFIERS void __prefetch_global_l1(const void* const ptr)
{
asm("prefetch.global.L1 [%0];" : : PXL_GLOBAL_PTR(ptr));
}
DEVICE_STATIC_INTRINSIC_QUALIFIERS void __prefetch_global_uniform(const void* const ptr)
{
asm("prefetchu.L1 [%0];" : : PXL_GLOBAL_PTR(ptr));
}
DEVICE_STATIC_INTRINSIC_QUALIFIERS void __prefetch_global_l2(const void* const ptr)
{
asm("prefetch.global.L2 [%0];" : : PXL_GLOBAL_PTR(ptr));
}