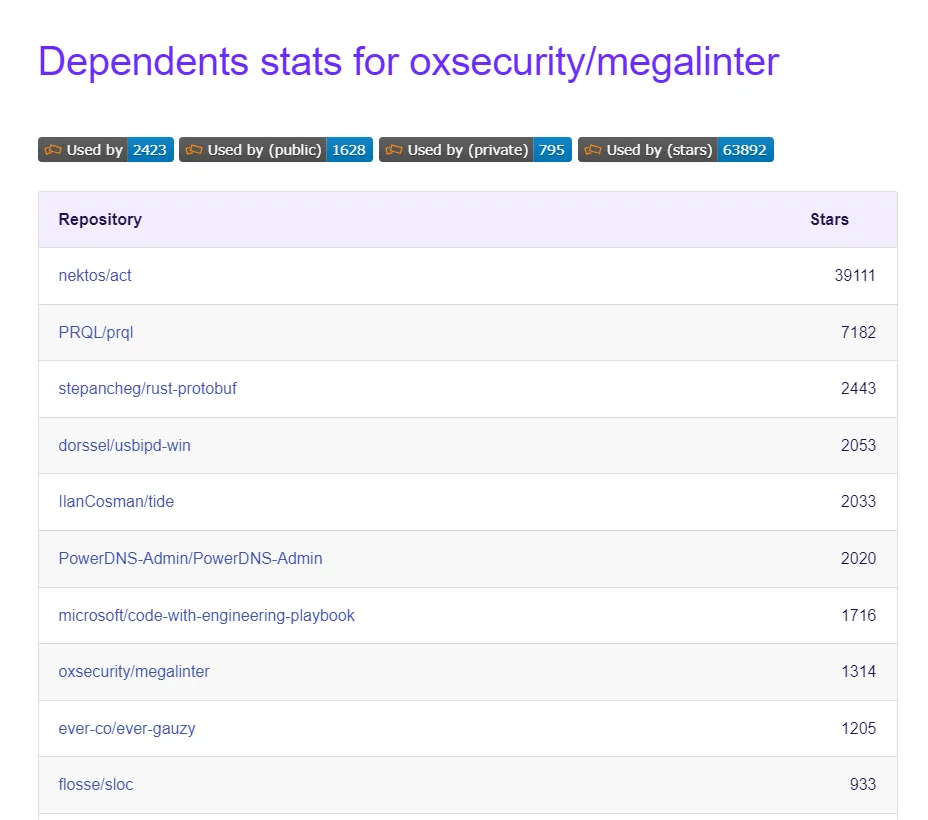
当我使用GitHub API v4获取某些信息时,可以通过使用
我想知道是否有可能以某种方式获取GitHub存储库中的依赖项信息?无论是使用GitHub API还是其他方式。
repository.dependencyGraphManifests轻松获取依赖项。但是我找不到任何方法可以使用GitHub API V4来获取依赖项的信息,尽管我可以在 Insights->Dependency Graph->Dependents中看到它。我想知道是否有可能以某种方式获取GitHub存储库中的依赖项信息?无论是使用GitHub API还是其他方式。