我一直在研究Windows和Linux(Debian)中一些C++ REST API框架的内存使用情况。特别是我看过这两个框架:cpprestsdk和cpp-httplib。在这两个框架中,都创建了一个线程池用于处理请求。
我从cpp-httplib中获取了线程池实现,并将其放入下面的最小工作示例中,以展示我在Windows和Linux上观察到的内存使用情况。
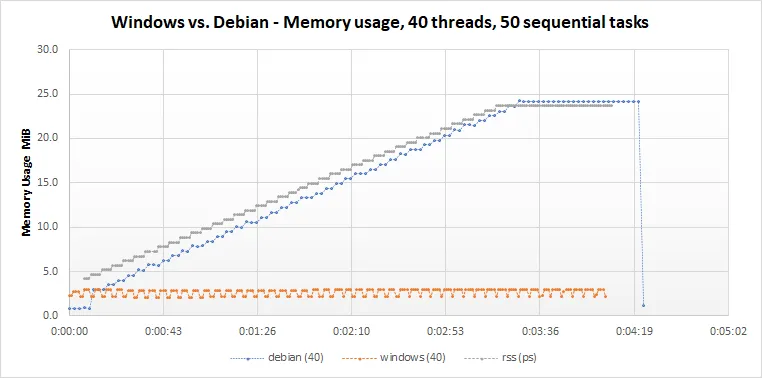
当我运行此MWE并查看Windows和Linux中的内存消耗时,我得到下面的图表。对于Windows,我使用
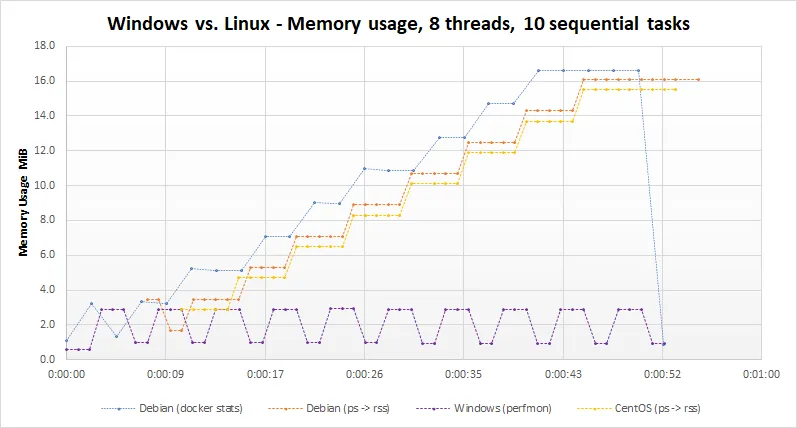
我在这里得到了相同的行为。我在示例中将线程数减少到8,任务数减少到10。下面的图表显示了结果。 编辑3:我已经添加了在Linux CentOS机器上运行的结果。它与Debian docker镜像结果基本一致。
我无法将第一张图片中的
我从cpp-httplib中获取了线程池实现,并将其放入下面的最小工作示例中,以展示我在Windows和Linux上观察到的内存使用情况。
#include <cassert>
#include <condition_variable>
#include <functional>
#include <iostream>
#include <list>
#include <map>
#include <memory>
#include <mutex>
#include <string>
#include <thread>
#include <vector>
using namespace std;
// TaskQueue and ThreadPool taken from https://github.com/yhirose/cpp-httplib
class TaskQueue {
public:
TaskQueue() = default;
virtual ~TaskQueue() = default;
virtual void enqueue(std::function<void()> fn) = 0;
virtual void shutdown() = 0;
virtual void on_idle() {};
};
class ThreadPool : public TaskQueue {
public:
explicit ThreadPool(size_t n) : shutdown_(false) {
while (n) {
threads_.emplace_back(worker(*this));
cout << "Thread number " << threads_.size() + 1 << " has ID " << threads_.back().get_id() << endl;
n--;
}
}
ThreadPool(const ThreadPool&) = delete;
~ThreadPool() override = default;
void enqueue(std::function<void()> fn) override {
std::unique_lock<std::mutex> lock(mutex_);
jobs_.push_back(fn);
cond_.notify_one();
}
void shutdown() override {
// Stop all worker threads...
{
std::unique_lock<std::mutex> lock(mutex_);
shutdown_ = true;
}
cond_.notify_all();
// Join...
for (auto& t : threads_) {
t.join();
}
}
private:
struct worker {
explicit worker(ThreadPool& pool) : pool_(pool) {}
void operator()() {
for (;;) {
std::function<void()> fn;
{
std::unique_lock<std::mutex> lock(pool_.mutex_);
pool_.cond_.wait(
lock, [&] { return !pool_.jobs_.empty() || pool_.shutdown_; });
if (pool_.shutdown_ && pool_.jobs_.empty()) { break; }
fn = pool_.jobs_.front();
pool_.jobs_.pop_front();
}
assert(true == static_cast<bool>(fn));
fn();
}
}
ThreadPool& pool_;
};
friend struct worker;
std::vector<std::thread> threads_;
std::list<std::function<void()>> jobs_;
bool shutdown_;
std::condition_variable cond_;
std::mutex mutex_;
};
// MWE
class ContainerWrapper {
public:
~ContainerWrapper() {
cout << "Destructor: data map is of size " << data.size() << endl;
}
map<pair<string, string>, double> data;
};
void handle_post() {
cout << "Start adding data, thread ID: " << std::this_thread::get_id() << endl;
ContainerWrapper cw;
for (size_t i = 0; i < 5000; ++i) {
string date = "2020-08-11";
string id = "xxxxx_" + std::to_string(i);
double value = 1.5;
cw.data[make_pair(date, id)] = value;
}
cout << "Data map is now of size " << cw.data.size() << endl;
unsigned pause = 3;
cout << "Sleep for " << pause << " seconds." << endl;
std::this_thread::sleep_for(std::chrono::seconds(pause));
}
int main(int argc, char* argv[]) {
cout << "ID of main thread: " << std::this_thread::get_id() << endl;
std::unique_ptr<TaskQueue> task_queue(new ThreadPool(40));
for (size_t i = 0; i < 50; ++i) {
cout << "Add task number: " << i + 1 << endl;
task_queue->enqueue([]() { handle_post(); });
// Sleep enough time for the task to finish.
std::this_thread::sleep_for(std::chrono::seconds(5));
}
task_queue->shutdown();
return 0;
}
当我运行此MWE并查看Windows和Linux中的内存消耗时,我得到下面的图表。对于Windows,我使用
perfmon获取Private Bytes值。在Linux中,我使用docker stats --no-stream --format "{{.MemUsage}}记录容器的内存使用情况。这与容器内运行的top进程的res相一致。从图表上看,在Windows中,当线程为handle_post函数中的map变量分配内存时,在函数退出之前给出内存,直到下一次调用该函数。这是我天真地期望的行为类型。我没有关于操作系统如何处理由在线程中执行的函数分配的内存的经验,当线程保持活动状态时,即像这里在线程池中。在Linux上,似乎内存使用情况不断增长,并且在函数退出时内存不会被归还。当使用了所有40个线程并且还有10个任务需要处理时,内存使用情况似乎停止增长。有人能够从内存管理的角度高层次地介绍在Linux中发生了什么,甚至提供一些指向特定主题背景信息的指针吗?
编辑1:我已经编辑下面的图表,以显示在运行ps -p <pid> -h -o etimes,pid,rss,vsz命令时每秒输出的rss值,在Linux容器中进行测试的进程的id为<pid>。它与docker stats --no-stream --format "{{.MemUsage}}的输出基本一致。
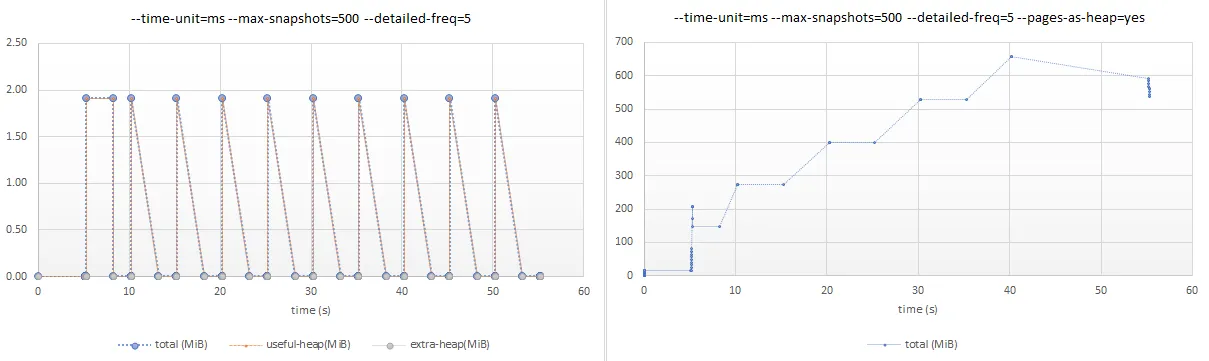
handle_post函数并添加#include <cstdlib>和#include <cstring>来删除了MWE中的映射。现在,handle_post函数只是为大约500K个int分配并设置内存,大约为2MiB。void handle_post() {
size_t chunk = 500000 * sizeof(int);
if (int* p = (int*)malloc(chunk)) {
memset(p, 1, chunk);
cout << "Allocated and used " << chunk << " bytes, thread ID: " << this_thread::get_id() << endl;
cout << "Memory address: " << p << endl;
unsigned pause = 3;
cout << "Sleep for " << pause << " seconds." << endl;
this_thread::sleep_for(chrono::seconds(pause));
free(p);
}
}
我在这里得到了相同的行为。我在示例中将线程数减少到8,任务数减少到10。下面的图表显示了结果。 编辑3:我已经添加了在Linux CentOS机器上运行的结果。它与Debian docker镜像结果基本一致。
valgrind的massif工具下运行了示例。 massif命令行参数如下图所示。我使用--pages-as-heap=yes参数运行了第二张图片,没有使用这个参数的是第一张图片。第一张图片表明当handle_post函数在一个线程上执行并在函数退出时被释放时,大约分配了 ~2MiB 的内存到(共享)堆中。这是我预期的,并且在Windows上观察到的情况。我还不确定如何解释使用--pages-as-heap=yes的图形,即第二张图片。我无法将第一张图片中的
massif 输出与上面图表中 ps 命令中的 rss 值协调。如果我运行 Docker 镜像并使用 docker run --rm -it --privileged --memory="12m" --memory-swap="12m" --name=mwe_test cpp_testing:1.0 限制容器内存为 12MB,那么容器将在第七次分配内存时耗尽内存并被操作系统杀死。输出中会出现 Killed,当我查看 dmesg 时,我看到 Killed process 25709 (cpp_testing) total-vm:529960kB, anon-rss:10268kB, file-rss:2904kB, shmem-rss:0kB。这表明 ps 中的 rss 值准确地反映了进程实际使用的(堆)内存,而 massif 工具则基于 malloc/new 和 free/delete 调用计算应该使用的内存。这只是我从这个测试中得出的基本假设。我的问题仍然存在,即:当 handle_post 函数退出时,为什么堆内存没有被释放或销毁?
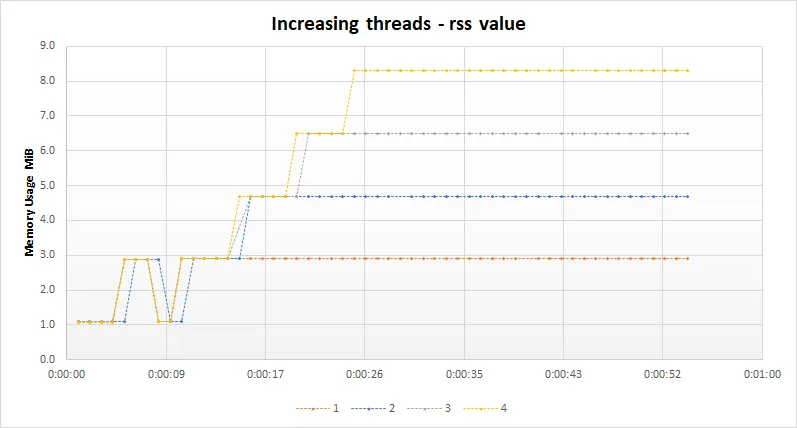
编辑5:我在下面添加了一张图表,展示了当你将线程池中的线程数从1个增加到4个时内存使用情况的变化。随着线程数量的增加,这种模式会持续下去,所以我没有包括5到10个线程。请注意,在main的开始处我添加了一个5秒的暂停,这是图表中前约5秒钟的初始水平线。似乎无论线程数如何,第一个任务处理后都会释放一些内存,但在2到10个任务之后该内存不会被释放(保留以供重用?)。这可能表明在任务1执行期间调整了某些内存分配参数(只是随口想想!)?
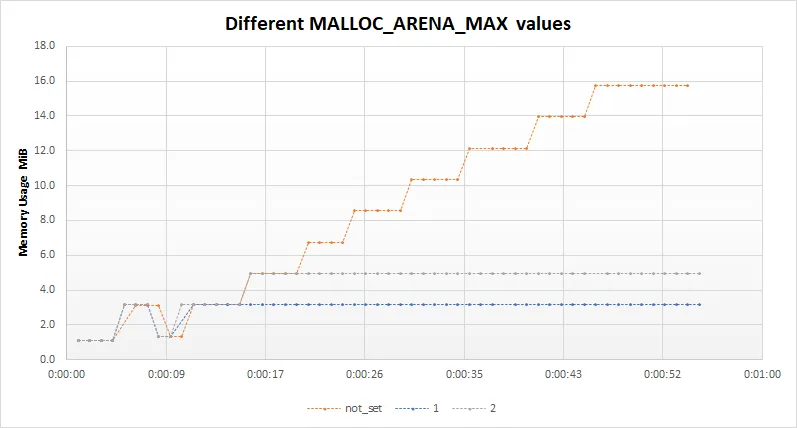
编辑6: 根据详细答案下面的建议,我在运行示例之前将环境变量MALLOC_ARENA_MAX设置为1和2。这将产生以下图表中的输出。根据答案中给出的此变量影响的解释,这是预期的结果。
handle_post中添加到地图中的元素数量从5K增加到50K,则Linux行会呈线性增长,直到达到约140 MB才会变平,而Windows行则保持在约13 MB,并在处理每个任务后下降。这就是让我感到困惑的地方。尽管在函数退出时包装地图的结构体的析构函数被调用,但似乎分配的内存仍然在使用中。再次说明,我在这方面经验很少,可能只是有一个非常基本的误解。 - Francisvalgrind的massif工具更新了问题的输出。使用--pages-as-heap=no的结果让我感到困惑。它显示了我所期望的行为,但是当我在限制容器内存后对其进行压力测试时,操作系统会杀死该进程。如果我根据massif输出来判断,我会期望容器的内存使用量保持在 ~2MB 左右。可能只是我对ps中的rss显示的内容与进程在堆上分配的内存量之间存在一些理解上的差距。 - Francishandle_post中调用free时,内存不一定会被返回给操作系统,因此massif和rss之间存在差异。如果内存大小增加,并且在 Linux 机器上运行,您觉得操作系统是否会在开始耗尽内存时重新获取已释放的空间? - Francis