有人能帮我将sql字符串转换为Dax吗?
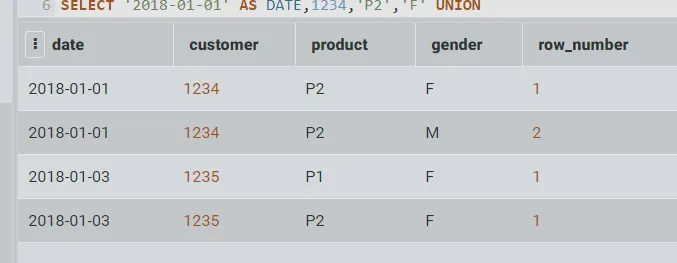
row_number() p over (partition by date, customer, type order by day)
行号是我想要的输出结果。
假设你的数据看起来像这个表格:
Sample
+------------+----------+---------+--------+
| Date | Customer | Product | Gender |
+------------+----------+---------+--------+
| 01/01/2018 | 1234 | P2 | F |
| 01/01/2018 | 1234 | P2 | M |
| 03/01/2018 | 1235 | P1 | F |
| 03/01/2018 | 1235 | P2 | F |
+------------+----------+---------+--------+
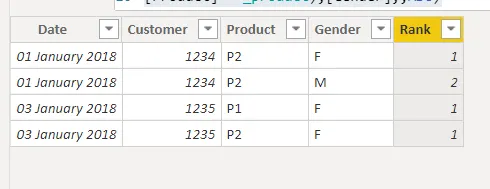
我创建了一个名为Rank的计算列,使用RANKX和FILTER函数。
计算的第一部分是在FILTER函数的范围之外创建变量。第二部分使用RANKX函数,它接受一个表达式值 - 在这种情况下是性别 - 来排序数值。
Rank =
VAR _currentdate = 'Sample'[Date]
VAR _customer = 'Sample'[Customer]
var _product = 'Sample'[Product]
return
RANKX(FILTER('Sample',
[Date]=_currentdate &&
[Customer] = _customer &&
[Product] = _product),[Gender],,ASC)
select
*,
row_number() over(partition by Date,Customer,Product order by Gender)
from (
select '2018-01-01' as Date,1234 as CUSTOMER,'P2' AS PRODUCT, 'M' Gender union
select '2018-01-01' as Date,1234,'P2','F' UNION
select '2018-01-03' as Date,1235,'P1','F' UNION
select '2018-01-03' as Date,1235,'P2','F'
)t1