import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
from sklearn.preprocessing import MinMaxScaler
from sklearn.compose import ColumnTransformer
data = [[1, 3, 4, 'text', 'pos'], [9, 3, 6, 'text more', 'neg']]
data = pd.DataFrame(data, columns=['Num1', 'Num2', 'Num3', 'Text field', 'Class'])
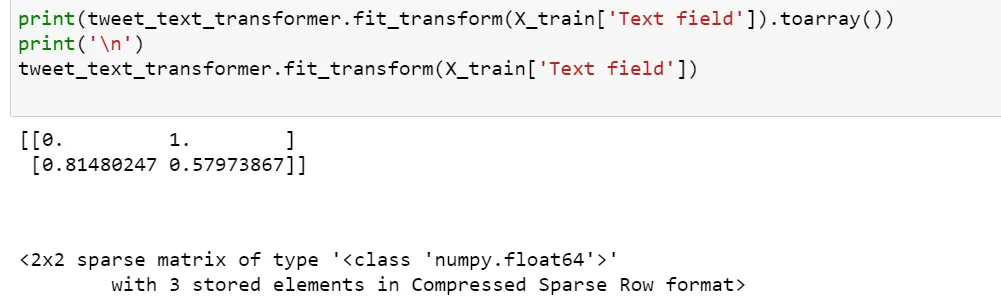
tweet_text_transformer = Pipeline(steps=[
('count_vectoriser', CountVectorizer()),
('tfidf', TfidfTransformer())
])
numeric_transformer = Pipeline(steps=[
('scaler', MinMaxScaler())
])
preprocessor = ColumnTransformer(transformers=[
# (name, transformer, column(s))
('tweet', tweet_text_transformer, ['Text field']),
('numeric', numeric_transformer, ['Num1', 'Num2', 'Num3'])
])
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LinearSVC())
])
X_train = data.loc[:, 'Num1':'Text field']
y_train = data['Class']
pipeline.fit(X_train, y_train)
我不明白这个错误是从哪里来的:
值错误:连接轴上的所有输入数组维度必须完全匹配,但在第 0 维上,索引为 0 的数组大小为 1,索引为 1 的数组大小为 2。
{kind=link}