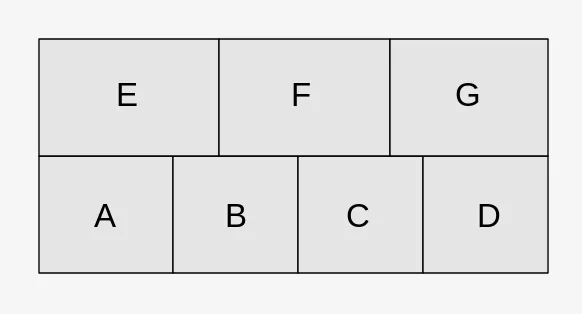
E F G
A B C D
在您发布的这个具体示例中,有两种方式可以排列
ABE和
CDG,而且这两组可以以任何方式交织在一起。
4 * (3 + 4 - 1) choose 3 = 80
现在我们只需要在B和C之后放置F。分析F的索引分布,我们得到:
{2: 12, 3: 36, 4: 64, 5: 80, 6: 80}
尝试为这个特定的依赖关系制定一个公式,就像你所建议的那样,是“混乱”的。在这种情况下,我可能会先生成前两个金字塔的交错,然后计算在每个金字塔中放置
F 的方法数,因为组合解法似乎同样复杂。
要通常扩展这样的问题,可以通过对图形进行搜索并利用对称性来解决。在这种情况下,从
A 开始就类似于从
D 开始;
B 与
C 相同。
Python 示例:
nodes = {
'A': {
'neighbours': ['B','C','D','E','F','G'], 'dependency': set()},
'B': {
'neighbours': ['A','C','D','E','F','G'], 'dependency': set()},
'C': {
'neighbours': ['A','B','D','E','F','G'], 'dependency': set()},
'D': {
'neighbours': ['A','B','C','E','F','G'], 'dependency': set()},
'E': {
'neighbours': ['C','D','F','G'], 'dependency': set(['A','B'])},
'F': {
'neighbours': ['A','D','E','G'], 'dependency': set(['B','C'])},
'G': {
'neighbours': ['A','B','E','F'], 'dependency': set(['C','D'])}
}
def f(key, visited):
if len(visited) + 1 == len(nodes):
return 1
if nodes[key]['dependency'] and not nodes[key]['dependency'].issubset(visited):
return 0
result = 0
for neighbour in nodes[key]['neighbours']:
if neighbour not in visited:
_visited = visited.copy()
_visited.add(key)
result += f(neighbour, _visited)
return result
print 2 * f('A', set()) + 2 * f('B', set())