这是我想出的一个算法片段:
for (int i = 0; i < n - 1; i++)
for (int j = i; j < n; j++)
(...)
我正在使用这个“双循环”来测试一个大小为n的数组中所有可能的2元素和。
显然(我必须同意),这个“双循环”是O(n²)的:
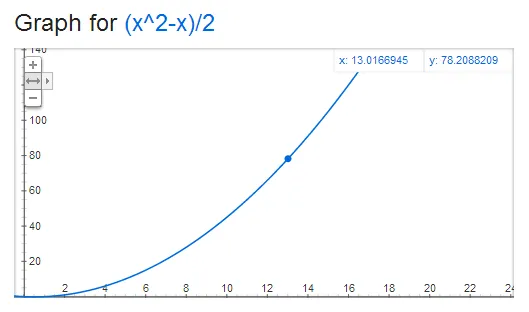
n + (n-1) + (n-2) + ... + 1 = sum from 1 to n = (n (n - 1))/2
以下是我感到困惑的地方:
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
(...)
这个第二个“双重循环”的复杂度也是
O(n²),但它明显(最坏情况下)比第一个更好。我错过了什么?这个信息准确吗?有人能解释一下这个“现象”吗?