我正在使用scikit learn,并且想要绘制精确度和召回率曲线。我正在使用的分类器是RandomForestClassifier。在scikit learn文档中的所有资源都使用二元分类。而且,我能否绘制多类别的ROC曲线?
此外,我只发现SVM用于多标签,并且它有一个decision_function,但RandomForest没有。
我正在使用scikit learn,并且想要绘制精确度和召回率曲线。我正在使用的分类器是RandomForestClassifier。在scikit learn文档中的所有资源都使用二元分类。而且,我能否绘制多类别的ROC曲线?
此外,我只发现SVM用于多标签,并且它有一个decision_function,但RandomForest没有。
从scikit-learn文档中:
精度-召回曲线通常用于二元分类,以研究分类器的输出。为了将精度-召回曲线和平均精度扩展到多类或多标签分类,需要对输出进行二值化。每个标签可以绘制一条曲线,但也可以通过将标签指示矩阵的每个元素视为二进制预测(微平均)来绘制精度-召回曲线。
ROC曲线通常用于二元分类,以研究分类器的输出。为了将ROC曲线和ROC面积扩展到多类或多标签分类,需要对输出进行二值化。每个标签可以绘制一条ROC曲线,但也可以通过将标签指示矩阵的每个元素视为二进制预测(微平均)来绘制ROC曲线。
因此,您应该将输出二值化,并考虑每个类别的精确率-召回率和ROC曲线。此外,您将使用predict_proba来获取类概率。
我将代码分为三部分:
1. 一般设置、学习和预测
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import precision_recall_curve, roc_curve
from sklearn.preprocessing import label_binarize
import matplotlib.pyplot as plt
#%matplotlib inline
mnist = fetch_openml("mnist_784")
y = mnist.target
y = y.astype(np.uint8)
n_classes = len(set(y))
Y = label_binarize(mnist.target, classes=[*range(n_classes)])
X_train, X_test, y_train, y_test = train_test_split(mnist.data,
Y,
random_state = 42)
clf = OneVsRestClassifier(RandomForestClassifier(n_estimators=50,
max_depth=3,
random_state=0))
clf.fit(X_train, y_train)
y_score = clf.predict_proba(X_test)
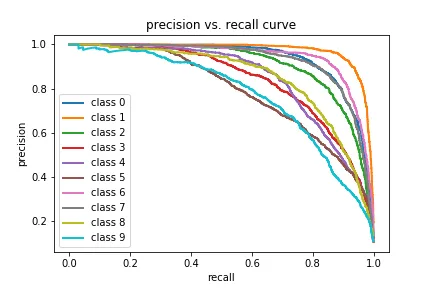
2. 精度-召回率曲线
# precision recall curve
precision = dict()
recall = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i],
y_score[:, i])
plt.plot(recall[i], precision[i], lw=2, label='class {}'.format(i))
plt.xlabel("recall")
plt.ylabel("precision")
plt.legend(loc="best")
plt.title("precision vs. recall curve")
plt.show()
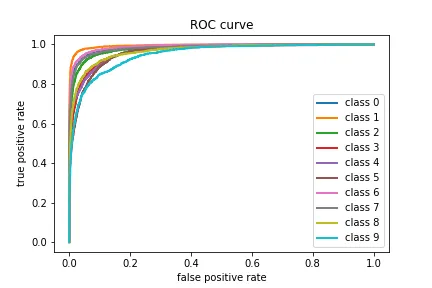
3. ROC 曲线
# roc curve
fpr = dict()
tpr = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i],
y_score[:, i]))
plt.plot(fpr[i], tpr[i], lw=2, label='class {}'.format(i))
plt.xlabel("false positive rate")
plt.ylabel("true positive rate")
plt.legend(loc="best")
plt.title("ROC curve")
plt.show()
Y = label_binarize(mnist.target, classes=[*range(n_classes)]),您应该在数据集中提供类别。在我的例子中,类别为 [0,1,2,...,9]。 - sentence