补充
在之前的Prolog SO答案中,我记得是由mat提供的一个Prolog谓词来分析Prolog术语并展示它过于复杂。
特别是对于像
[op(add),[[number(0)],[op(add),[[number(1)],[number(1)]]]]]
它揭示了这有太多的[]。
我搜索了我的Prolog问题并查看了答案两次,仍然找不到它。我还记得它不在SWI-Prolog中,而是在另一个Prolog中,所以我能够使用Prolog的在线版本来使用谓词。
如果您阅读评论,您将看到mat确定了我正在寻找的帖子。
我所追求的是什么
在选择表达方式方面,我有最后一点建议。请尝试以下内容,例如使用GNU Prolog或任何其他符合Prolog标准的系统:
| ?- write_canonical([op(add),[Left,Right]]).
'.'(op(add),'.'('.'(_18,'.'(_19,[])),[]))
这表明这种表示方式相当 浪费,同时阻碍了对生成的所有表达式的统一处理,结合了几个缺点。
你可以通过使用Left+Right或使用op_arguments(add, [Left,Right])、op_arguments(number, [1])等方法,使其更加紧凑和统一。
一个 Prolog 数据结构的演化
如果你还不知道,这个问题与在 Prolog 中编写一个符号数学术语重写系统有关,我目前主要集中于简化重写。
大多数人只看到以自然表示的数学表达式。
x + 0 + sin(y)
计算机程序员意识到大多数编程语言在使用前必须解析数学表达式并将其转换为AST。
add(add(X,0),sin(Y))
但是大多数编程语言不能直接使用上述AST,必须创建数据结构。参见: 编译器/词法分析器, 编译器/语法分析器, 编译器/抽象语法树解释器。
现在,如果你在学习Prolog时不仅仅是浅尝辄止,那么你一定会遇到导数规则程序3.30,它包含在这里,但该人没有给出归属。
如果你试图使用Prolog编写自己的符号数学代码,你可能会尝试使用is/2,但很快就会发现它不起作用,然后发现Prolog可以将以下内容读取为复合术语。
add(add(X,0),sin(Y))
这开始运作,直到你需要访问函数对象的名称并找到functor/3,但随后我们又回到了需要解析输入的情况。不过正如mat所指出的以及在"Prolog艺术"中提到的,如果有人使结构的名称可访问,就可以避免这个问题。
op(add,(op(add,X,0),op(sin,Y)))
现在,人们可以以Prolog友好的方式访问表达式中的运算符和术语。如果没有旁注的话,代码仍将使用嵌套列表数据结构,并且现在正在转换为使用公共项术语来公开结构名称。我想知道是否有一个常见的短语来描述这个,如果没有,应该有一个。无论如何,新的简单数据结构已经通过了第一组测试,现在需要看看它在项目进一步开发时是否能够保持稳定。
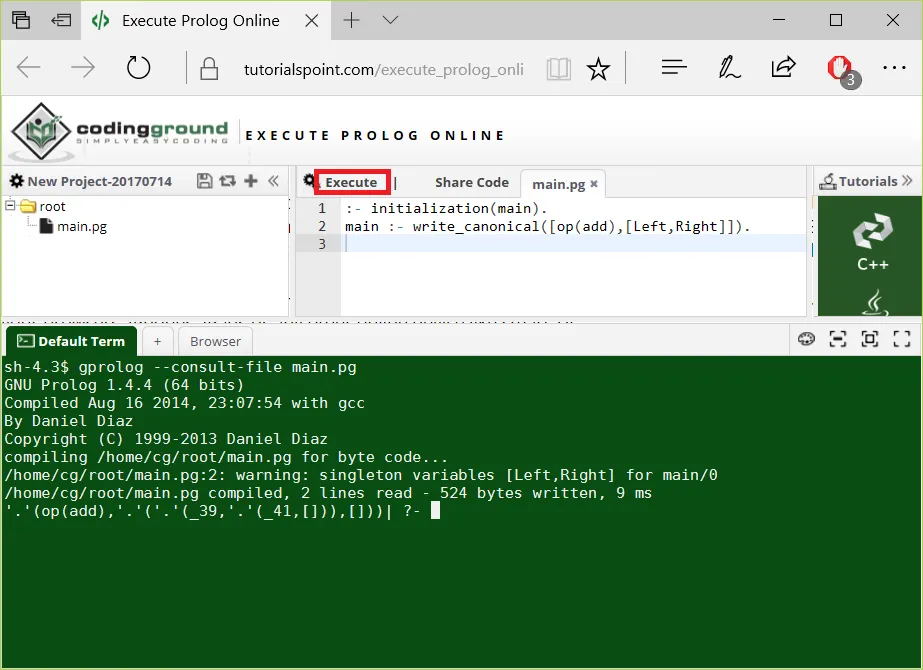
请在tutorialspoint.com上使用GNU Prolog进行在线尝试
:- initialization(main).
main :- write_canonical([op(add),[Left,Right]]).
然后点击执行并查看输出。
sh-4.3$ gprolog --consult file main.pg
GNU Prolog 1.4.4 (64 bits)
Compiled Aug 16 2014, 23:07:54 with gcc
By Daniel Diaz
Copyright (C) 1999-2013 Daniel Diaz
compiling /home/cg/root/main.pg for byte code...
/home/cg/root/main.pg:2: warning: singleton variables [Left,Right] for main/0
/home/cg/root/main.pg compiled, 2 lines read - 524 bytes written, 9 ms
'.'(op(add),'.'('.'(_39,'.'(_41,[])),[]))| ?-
来自《Prolog之力》(The Power of Prolog),作者:Markus Triska
在使用Prolog术语表示数据时,请问自己以下问题:
我能否通过最外层的函数符和元数来区分每个成分的类型?
如果满足这个条件,那么你的表示方法被称为是清晰表示。如果你不能通过它们的最外层函数符和元数来区分元素,则被称为缺省表示,这是一个将"default"和"faulty"组合起来的单词游戏。这是因为关于你的数据的推理需要一个"缺省情况",如果其他所有情况都失败了则应用它。此外,这种表示方法防止了参数索引,并且由于这一缺点被认为是有问题的。始终致力于避免缺省表示!而是努力寻求更清晰的表示方法。
a,您可以轻松地认为像[[a]]这样的表示方式过于复杂(列表结构是多余/不必要的)。然而,在更广泛的背景下,如果[[a]]是为给定应用程序定义的更复杂结构的微不足道的情况,那么它可能是合适的。那么...“过于复杂”的定义是什么? - lurker