我有一个大小为(21760, 1, 33, 33)的hdf5训练数据集。21760是训练样本的总数。我想使用大小为128的小批量训练数据来训练网络。
我想问:
如何使用tensorflow每次从整个数据集中提取128个小批量训练数据?
我有一个大小为(21760, 1, 33, 33)的hdf5训练数据集。21760是训练样本的总数。我想使用大小为128的小批量训练数据来训练网络。
我想问:
如何使用tensorflow每次从整个数据集中提取128个小批量训练数据?
如果你的数据集太大而无法像 keveman 建议的那样导入内存,你可以直接使用 h5py 对象:
import h5py
import tensorflow as tf
data = h5py.File('myfile.h5py', 'r')
data_size = data['data_set'].shape[0]
batch_size = 128
sess = tf.Session()
train_op = # tf.something_useful()
input = # tf.placeholder or something
for i in range(0, data_size, batch_size):
current_data = data['data_set'][position:position+batch_size]
sess.run(train_op, feed_dict={input: current_data})
如果您想的话,还可以运行大量迭代并随机选择一批:
import random
for i in range(iterations):
pos = random.randint(0, int(data_size/batch_size)-1) * batch_size
current_data = data['data_set'][pos:pos+batch_size]
sess.run(train_op, feed_dict={inputs=current_data})
或者按顺序:
for i in range(iterations):
pos = (i % int(data_size / batch_size)) * batch_size
current_data = data['data_set'][pos:pos+batch_size]
sess.run(train_op, feed_dict={inputs=current_data})
你可能希望编写一些更复杂的代码,随机地遍历所有数据,但要跟踪已使用的批次,以便不会比其他批次使用更频繁。在对整个训练集进行完整运行后,重新启用所有批次并重复执行。
import numpy, h5py
f = h5py.File('somefile.h5','r')
data = f.get('path/to/my/dataset')
data_as_array = numpy.array(data)
for i in range(0, 21760, 128):
sess.run(train_op, feed_dict={input:data_as_array[i:i+128, :, :, :]})
i很大,例如100000时,如何进行喂养? - karl_TUM21760个训练样本,那么你只有21760/128个不同的小批次。你需要在i循环外编写一个外部循环,并在训练数据集上运行多个时期。 - kevemanalkamen's 的方法在逻辑上似乎是正确的,但我使用它没有得到任何积极的结果。我最好的猜测是:在上面的代码示例1中,在每次迭代中,网络都会重新训练,忘记了之前学到的所有内容。因此,如果我们每次迭代获取30个样本或批次,那么在每次循环/迭代中,只有30个数据样本被使用,然后在下一次循环中,所有内容都被覆盖。
以下是这种方法的屏幕截图
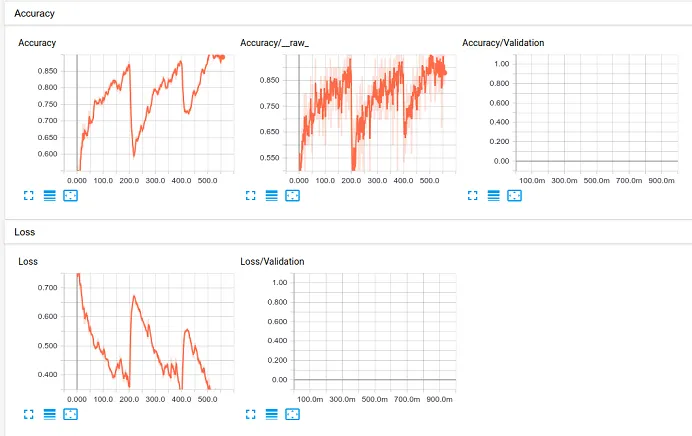
如图所示,损失和准确性总是重新开始。如果有人能分享可能的解决方法,我将不胜感激。